Linux
Linux
- Bond en debian
- Borrar archivos de más de X días
- Comandos Linux
- Comandos para buscar ficheros
- Comandos para Logs
- Cómo buscar texto en todas las carpetas de un directorio en linux
- Como comprimir y descomprimir .tar .tar.gz .tgz .gz .zip y otras en Linux
- Cómo generar una clave SSH en Linux
- Cómo hacer una copia de seguridad de todo un sistema Linux usando Rsync
- Configurar Interfaz pppoe Linux
- Configurar Interfaz Wifi Linux
- Configurar iptables
- Configurar la zona horaria en Linux
- Configurar ntp
- Configurar un servidor FTP con vsftpd
- Fail2ban
- Ipmi linux
- Kill
- Listar archivos grandes linux
- Procesos Linux ps
- Redimensionar un disco en Linux
- rsync
- Uso de atop
- Usuarios y grupos en Linux
- Personalizar bash mediante .bashrc
- Permisos extendidos de archivos en linux
- Tipos de archivo en Linux por función
- Atributos extendidos en los ficheros de Linux
- Filtrado de paquetes en Linux
- Iscsi debian
- Balanceador con HAProxy y Keepalived
- Instalar Memcached
- Suspensión del HDD en Linux hdparm
- Parsear logs
- Netstat
- Túnel SSH
- Localizar un disco físico mediante el led de actividad
- rsync
- Instalar Redis
- Instalar Chrony en Debian
- Encontrar el número de serie de un disco en Linux
- Obtener el Número de Serie y el Modelo de un servidor en Linux - DMIDECODE
- Update desde debian 11 a debian12
- Fichero de configuración para SSH
Bond en debian
Como crear un bond en Debian
Referencias:
https://wiki.debian.org/Bonding
https://www.kernel.org/doc/Documentation/networking/bonding.txt
apt-get install ifenslave # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). # The loopback network interface auto lo iface lo inet loopback # The primary network interface # allow-hotplug eth0 # iface eth0 inet dhcp auto bond0 iface bond0 inet static bond-mode 4 bond-miimon 100 bond_xmit_hash_policy layer2+3 bond_lacp_rate fast slaves eth0 eth1 auto bond0.42 iface bond0.42 inet dhcp vlan_raw_device bond0
Borrar archivos de más de X días
Por ejemplo para borrar archivos de más de 30 días de antigüedad
find /ruta/de/los/archivos* -mtime +30 -type f -exec rm {} \;Comandos Linux
Comandos Linux
Comando screen
Screen es un programa muy útil que nos permite en una sola terminal de texto (consola, sesión telnet, etc.) tener hasta 10 ventanas (el equivalente a 10 terminales) haciendo diferentes tareas (shell en una, lector de correo o news en otra, etc.) y pudiendo cambiar entre ellas de una manera rápida y sencilla.
Screen suele venir en todas las distribuciones Linux. Una vez instalada la ejecutamos (screen) y ya podremos empezar a utilizarla.
Para usar SCREEN se usa el atajo de teclado ^A (Control-A). Cuando estemos en consola y queramos enviar una orden a screen (cambiar de "ventana", crear nuevas ventanas, etc.) se pulsa CTRL+A y a continuación la tecla del comando a enviar (soltando CTRL-A antes de pulsar la tecla de comando):
| Tecla | Comando |
|---|---|
| CTRL+a seguido de ? | Se obtiene una pequeña lista de comandos. |
| CTRL+a seguido de c | Se crea una nueva ventana (la inicial es la 0, luego 1, 2…). |
| CTRL+a seguido de un número 0-9 | Cambiamos la vista a la ventana especificada por el número. |
| CTRL+a seguido de n | Ir a la siguiente (next) ventana. |
| CTRL+a seguido de p | Ir a la siguiente (previous) ventana. |
| CTRL+a seguido de w | Obtenemos una lista de ventanas disponibles. |
Con exit cerramos la terminal en la que estemos. Al salir de screen (si hacemos un exit en la ultima terminal disponible) aparecerá el mensaje [screen is terminating].
Por ejemplo, es posible hacer lo siguiente:
[user@maquina] screen <CTRL+a>c -> Creamos terminal 1 [user@maquina] mutt -> Abrimos el mutt <CTRL+a>c -> Creamos terminal 2 [user@maquina] slrn -n -> Abrimos el slrn
Ahora podemos cambiar entre cualquiera de los 3 programas (mutt, slrn y una shell bash) mediante CTRL-A seguido del número 0 (bash), 1 (mutt) y 2 (slrn) ya que las hemos creado en ese orden. Podemos salir de cualquiera de los tres programas y estar bajo una shell bash disponiendo áun de dicha terminal (hasta que hagamos exit).
Otros comandos SCREEN más avanzados son:
| Tecla | Comando |
|---|---|
| CTRL+a seguido de k | Borrar la pantalla de la ventana actual |
| CTRL+a seguido de Ctrl+x | Bloquear la pantalla (pedirá la password del usuario). |
| CTRL+a seguido de :detach | Desvincular la pantalla de la sesión de screen. Podemos recuperarla luego con screen -r |
Notas
Screen soporta cosas mucho más complejas, como dettach de procesos, dejarlos corriendo en background al cerrar los terminales, etc. Consultar el manual de screen para más florituras.
Screen soporta copiado de pantallas, loggin, cut & paste, keybindings, bloqueado de consola (bloquea todas :), etc.
como la A está cerca de la S, puede ser que al hacer CTRL+a le demos a CTRL+s (comando STOP en las terminales TTY). En caso de que esto ocurra basta darle a CTRL+Q para detener el stop.
Comando sed
El comando SED
El comando sed SED (Stream EDitor) es un editor de flujos y ficheros de forma no interactiva. Permite modificar el contenido de las diferentes líneas de un fichero en base a una serie de comandos o un fichero de comandos (-f fichero_comandos). El comando sed de Linux edita datos basado en las reglas que tú le proporciones, puedes utilizarlo de la siguiente forma
$sed options file
Sed recibe por stdin (o vía fichero) una serie de líneas para manipular, y aplica a cada una de ellas los comandos que le especifiquemos a todas ellas, a un rango de las mismas, o a las que cumplan alguna condición.
Sustituir apariciones de cadena1 por cadena2 en todo el fichero:
# sed 's/cadena1/cadena2/g' fichero > fichero2
Sustituir apariciones de cadena1 por cadena2 en las líneas 1 a 10:
# comando | sed '1,10 s/cadena1/cadena2/g'
Eliminar las líneas 2 a 7 del fichero
# sed '2,7 d' fichero > fichero2
Buscar un determinado patrón en un fichero:
# sed -e '/cadena/ !d' fichero
Buscar AAA o BBB o CCC en la misma línea:
# sed '/AAA/!d; /BBB/!d; /CCC/!d' fichero
Buscar AAA y BBB y CCC:
# sed '/AAA.*BBB.*CCC/!d' fichero
Buscar AAA o BBB o CCC (en diferentes líneas, o grep -E):
# sed -e '/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d
# gsed '/AAA\|BBB\|CCC/!d'Formato de uso
El formato básico de uso de sed es:
# sed [-ns] '[direccion] instruccion argumentos'Donde:
- [direccion] es opcional, siendo un número de línea (N), rango de números de línea (N,M) o búsqueda de regexp (/cadena/) indicando el ámbito de actuación de las instrucciones. Si no se especifica [direccion], se actúa sobre todas las líneas del flujo.
- Instruccion puede ser:
- i = Insertar línea antes de la línea actual.
- a = Insertar línea después de la línea actual.
- c = Cambiar línea actual.
- d = Borrar línea actual.
- p = Imprimir línea actual en stdout.
- s = Sustituir cadena en línea actual.
- r fichero = Añadir contenido de "fichero" a la línea actual.
- w fichero = Escribir salida a un fichero.
- ! = Aplicar instrucción a las líneas no seleccionadas por la condición.
- q = Finalizar procesamiento del fichero.
- -n: No mostrar por stdout las líneas que están siendo procesadas.
- -s: Tratar todos los ficheros entrantes como flujos separados.
Ejemplos de sustitución
Reemplazar cadenas:
# sed 's/^Host solaris8/Host solaris9/g' fichero > fichero2
Reemplazar cadenas sólo en las lineas que contentan una cadena:
# sed '/cadena_a_buscar/ s/vieja/nueva/g' fichero > fichero2
Reemplazar cadenas sólo en en determinadas líneas:
# sed '5,6 s/vieja/nueva/g' fichero > fichero2
Reemplazar multiples cadenas (A o B):
# sed 's/cadenasrc1\|cadenasrc2/cadena_nueva/g'
Sustituir líneas completas (c) que cumplan o no un patrón:
# echo -e "linea 1\nlinea 2" | sed '/1/ cPrueba'
Prueba
linea 2
# echo -e "linea X 1\nlinea 2" | sed '/1/ !cPrueba'
linea 1
PruebaEjemplos de Inserción
Insertar 3 espacios en blanco al principio de cada línea:
# sed 's/^/ /' fichero
Añadir una línea antes o despues del final de un fichero ($=última línea):
# sed -e '$i Prueba' fichero > fichero2
# sed -e '$a Prueba' fichero > fichero2
Insertar una linea en blanco antes de cada linea que cumpla una regex:
# sed '/cadena/{x;p;x;}' fichero
Insertar una linea en blanco detras de cada linea que cumpla una regex:
# sed '/cadena/G' fichero
Insertar una linea en blanco antes y despues de cada linea que cumpla una regex:
# sed '/cadena/{x;p;x;G;}' fichero
Insertar una línea en blanco cada 5 líneas:
# sed 'n;n;n;n;G;' fichero
Insertar número de línea antes de cada línea:
# sed = filename | sed 'N;s/\n/\t/' fichero
Insertar número de línea, pero sólo si no está en blanco:
# sed '/./=' fichero | sed '/./N; s/\n/ /'
Si una línea acaba en \ (backslash) unirla con la siguiente:
# sed -e :a -e '/\\$/N; s/\\\n//; ta' ficheroEjemplos de Selección/Visualización
Ver las primeras 10 líneas de un fichero:
# sed 10q
Ver las últimas 10 líneas de un fichero:
# sed -e :a -e '$q;N;11,$D;ba'
Ver un rango concreto de líneas de un fichero:
# cat -n fich2 | sed -n '2,3 p'
2 linea 2
3 linea 3
(Con cat -n, el comando cat agrega el número de línea).
(Con sed -n, no se imprime nada por pantalla, salvo 2,3p).
Ver un rango concreto de líneas de varios ficheros:
# sed '2,3 p' *
linea 2 fichero 1
linea 3 fichero 1
linea 2 fichero 2
linea 3 fichero 2
(-s = no tratar como flujo sino como ficheros separados)
Sólo mostrar la primera linea de un fichero:
# sed -n '1p' fichero > fichero2.txt
No mostrar la primera linea de un fichero:
# sed '1d' fichero > fichero2.txt
Mostrar la primera/ultima línea de un fichero:
# sed -n '1p' fichero
# sed -n '$p' fichero
Imprimir las líneas que no hagan match con una regexp (grep -v):
# sed '/regexp/!d' fichero
# sed -n '/regexp/p' fichero
Mostrar la línea que sigue inmediatamente a una regexp:
# sed -n '/regexp/{n;p;}' fichero
Mostrar desde una expresión regular hasta el final de fichero:
# sed -n '/regexp/,$p' fichero
Imprimir líneas de 60 caracteres o más:
# sed -n '/^.\{60\}/p' fichero
Imprimir líneas de 60 caracteres o menos:
# sed -n '/^.\{65\}/!p' fichero
# sed '/^.\{65\}/d' ficheroEjemplos de Borrado
Eliminar un rango concreto de líneas de un fichero:
# sed '2,4 d' fichero > fichero2.txt
Eliminar todas las líneas de un fichero excepto un rango:
# sed '2,4 !d' fichero > fichero2.txt
Eliminar la última línea de un fichero
# sed '$d' fichero
Eliminar desde una línea concreta hasta el final del fichero:
# sed '2,$d' fichero > fichero2.txt
Eliminar las líneas que contentan una cadena:
# sed '/cadena/ d' fichero > fichero2.txt
# sed '/^cadena/ d' fichero > fichero2.txt
# sed '/^cadena$/ d' fichero > fichero2.txt
Eliminar líneas en blanco (variación del anterior):
# comando | sed '/^$/ d'
# sed '/^$/d' fichero > fichero2.txt
Eliminar múltiples líneas en blanco consecutivas dejando sólo 1:
# sed '/./,/^$/!d' fichero
Añadir una línea después de cada línea:
# echo -e "linea 1\nlinea 2" | sed 'aPrueba'
linea 1
Prueba
linea 2
Prueba
Eliminar espacios al principio de línea:
# sed 's/^ *//g' fichero
Eliminar todos los espacios que haya al final de cada línea:
# sed 's/ *$//' fichero
Eliminar espacios sobrantes a principio y final de línea, o ambos:
# sed 's/^[ \t]*//' fichero
# sed 's/[ \t]*$//' fichero
# sed 's/^[ \t]*//;s/[ \t]*$//' fichero
Eliminar tags HTML:
# sed -e :a -e 's/<[^>]*>//g;/</N;//ba' fichero
Borrar líneas duplicadas no consecutivas de un fichero:
# sed -n 'G; s/\n/&&/; /^\([ -~]*\n\).*\n\1/d; s/\n//; h; P' fichero
Eliminar líneas en blanco y comentarios bash:
# comando | sed '/^$/ d'
# sed '/^$/d; / *#/d' fichero > fichero2.txtUso de salida selectiva
Salir a nuestra voluntad antes de acabar el fichero:
# sed -e '/uno/ s/uno/1/' -e '/salir/ q' fichero > fichero2.txt
# sed 10q fichero
# sed q fichero
Equivalencia de -e con ";":
# sed -e '/AAA/b' -e '/BBB/b' -e 'd' == sed '/AAA/b;/BBB/b;d'
Usar 'q' apropiadamente reduce tiempo de procesamiento:
# sed -n '10,20p' fichero
# sed -n '21q;10,20p' fichero -> Más rápido que el anterior.
Conversión de CRLF de DOS a formato UNIX (LF):
# sed 's/.$//' fichero
Conversión de LF de UNIX a formato DOS (CRLF):
# sed 's/$'"/`echo \\\r`/" fichero
Obtener el Subject de un correo, pero sin cadena "Subject: ":
# sed '/^Subject: */!d; s///;q' fichero
Imprimir párrafo (cadenas entre 2 líneas en blanco) si contiene XXX:
# sed -e '/./{H;$!d;}' -e 'x;/XXX/!d;' fichero
Imprimir párrafo si contiene (1) XXX y ZZZ o bien (2) XXX o ZZZ :
# sed -e '/./{H;$!d;}' -e 'x;/XXX/!d;/ZZZ/!d'
# sed -e '/./{H;$!d;}' -e 'x;/XXX/b' -e '/ZZZ/b' -e d
Comando wc
El comando wc (word count) es un comando utilizado en Linux para realizar cuenta desde la línea de comando, permite contar palabras, caracteres, líneas.
Modo de uso
wc -l <fichero> número de líneas
wc -c <fichero> número de bytes
wc -m <fichero> imprime el número de caracteres
wc -L <fichero> imprime la longitud de la línea más larga
wc -w <fichero> imprime el número de palabrasEjemplo de uso
$ wc prueba1.txt prueba2.txt
40 149 947 prueba1.txt
2294 16638 97724 prueba2.txt
2334 16787 98671 totalCombinación con otros comandos
Concatenamos el contenido del archivo /var/log/maillog, con grep buscamos todas las líneas que contengan “usuario@dominio” en su contenido, y con wc -l contamos las líneas resultantes.
$ cat var/log/maillog | grep "usuario@dominio.com" | wc -l
40
Comandos para buscar ficheros
grep
grep 'texto_a_buscar' arch*
Busca el texto texto_a_buscar en todos los archivos arch*
grep -r pattern dir
Realiza una búsqueda recursiva
zgrep 'pattern' archivos
Busca en los archivos normales y en los comprimidos
Comandos para Logs
Uno de los recursos más utilizados para analizar problemas en sistemas Linux es la revisión de logs.
Vamos a ver algunas de las formas de revisar dichos logs. Como ejemplo vamos a ver el log de un servidor de correo Linux
Mostrar los últimos n registros de un log
tail -n 200 /var/log/maillog
Mostrar el log en tiempo real
tail -f /var/log/maillog
Mostrando un texto específico
En el archivo de log
tail -n 200 /var/log/maillog | grep 'texto_a_mostrar'
En tiempo real
tail -f /var/log/maillog | grep 'texto_a_mostrar'
Cómo buscar texto en todas las carpetas de un directorio en linux
Para buscar un determinado texto en Linux. existen dos formas de hacerlo
find awk '$1=="TEXTO_A_BUSCAR"{print$2}' /CARPETA *.html
La segunda forma es así
find /CARPETA -type f -exec grep -H 'TEXTO_A_BUSCAR' {} \;
Como comprimir y descomprimir .tar .tar.gz .tgz .gz .zip y otras en Linux
En cualquier distribución de Linux nos encontramos con una serie de herramientas para empaquetar y desempaquetar archivos. Vamos a ver las principales formas de comprimir y descomprimir archivos en Linux
Comprimir y descomprimir .tar (tar)
Para comprimir archivos .tar, debemos utilizar:
tar cvf archivo.tar /carpeta/archivos
Esto comprimirá todos los archivos en la carpeta /carpeta/ y sus subcarpetas Para descomprimir archivos .tar, debemos utilizar:
tar xvf archivo.tar
Comprimir y descomprimir .tar.gz .tar.z .tgz (tar con gzip)
Para comprimir .tar.gz o .tar.z o .tgz, debemos utilizar:
tar czvf archivo.tar.gz /carpeta/archivos
Para descomprimir .tar.gz o .tar.z o .tgz, debemos utilizar:
tar xzvf archivo.tar.gz
Comprimir y descomprimir .gz (gzip)
IMPORTANTE: gzip sólo comprime archivos, no directorios completos.
Para comprimir .gz, debemos utilizar:
gzip -q archivo
(El archivo comprime, y lo renombra como archivo.gz) Para descomprimir .gz, debemos utilizar:
gzip -d archivo.gz
Comprimir y descomprimir .bz2 (bzip2)
IMPORTANTE: Lo primero a tener en cuenta, es que bzip2 solo comprime archivos, no directorios
Para comprimir .bz2, debemos utilizar:
bzip2 archivo
Para descomprimir .bz2, debemos utilizar:
bzip2 -d archivo.bz2
Comprimir y descomprimir .zip (zip)
Para comprimir .zip, debemos utilizar:
zip archivo.zip /carpeta/archivos
Para descomprimir .zip, debemos utilizar:
unzip archivo.zip
Comprimir y descomprimir .rar (rar)
Para comprimir .rar, debemos utilizar:
rar -a archivo.rar /carpeta/archivos
Para descomprimir .rar, debemos utilizar:
rar -x archivo.rar
Cómo generar una clave SSH en Linux
La autenticación con clave pública para conectarse a un servidor remoto usando el protocolo SSH funciona con dos claves: una pública y otra privada. Para entender el funcionamiento se suele recurrir a la metáfora del candado y la llave. La clave pública funciona como un candado y la privada como la llave. El candado se colocará en el servidor remoto al que se quiere acceder; cuando se intenta acceder se comprobará que la máquina que intenta conectar tiene la llave, la clave privada.
Para configurar el acceso SSH con clave pública hay que:
Generar el par de claves pública/privada.
Copiar la clave pública al servidor.
Deshabilitar el acceso al servidor con contraseña.
Clientes Windows
Si necesitas crear el conjunto de claves en Windows con Putty, puedes encontrar la información aquí. Si usas el subsistema Linux en Windows, el proceso es igual que en Linux y se describe a continucación
CÓMO GENERAR EL PAR DE CLAVES PÚBLICA/PRIVADA
Para generar las claves se puede usar ssh-keygen en la máquina local desde la que se quiere conectar con el servidor:
# ssh-keygen -b 4096
Generating public/private rsa key pair.
Enter file in which to save the key (/home/usuario/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in id_rsa.
Your public key has been saved in id_rsa.pub.
The key fingerprint is:
SHA256:GKW7yzA1J1qkr1Cr9MhUwAbHbF2NrIPEgZXeOUOz3Us ylo@klar
The key's randomart image is:
+---[RSA 4096]----+
|.*++ o.o. |
|.+B + oo. |
| +++ *+. |
| .o.Oo.+E |
| ++B.S. |
| o * =. |
| + = o |
| + = = . |
| + o o |
+----[SHA256]-----+
#Pide la ruta y el nombre del archivo que alojará las claves pública y privada. Se puede guardar donde se quiera, pero la carpeta debe tener permisos 700 y el archivo con la clave privada 600. De lo contrario la conexión no se establecerá. La clave privada se puede proteger a su vez con una contraseña. De esta manera, si cae en manos no deseadas, lo tendrá un poco más difícil para usarla.
habitualmente se almacena en el directorio:
~/.sshssh-keygen generará dos archivos:
id_rsa es la clave privada, la que permanecerá en la máquina local.
id_rsa.pub es la clave pública, la que se tiene que copiar al servidor remoto al que se quiere acceder.
Generar una clave ED25519
Las claves ed25519 es una solución de criptografía relativamente nueva que implementa el algoritmo de firma digital de curva de Edwards (EdDSA). Es compatible con OpenSSH desde hace unos años, por lo que la mayoría de sistemas actuales soportan esta clave criptográfica
En comparación con el tipo más común de clave SSH, RSA, ed25519 trae una serie de mejoras interesantes:
- La generación y la verificación son más rápidas
- Es más segura
- Es más resistente contra los ataques de fuerza bruta en los que se generan gran cantidad de Hash a la espera de que alguno sea validado.
- Las claves son más pequeñas a la hora de hacer un copia/pega.
El procedimiento es sencillo:
ssh-keygen -t ed25519 -C "ateinco@ateinco.com"
Generating public/private ed25519 key pair.
Enter file in which to save the key (/home/users/eduardo/.ssh/id_ed25519):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/users/eduardo.ssh/id_ed25519.
Your public key has been saved in /home/users/eduardo/.ssh/id_ed25519.pub.
The key fingerprint is:
SHA256:FHsTXXXXXXXXXXXpw4o7+rp+M1yqMyBF8vXSBRkZtkQ0RKY ateinco@ateinco.com
The key's randomart image is:
+--[ED25519 256]--+
| */Xoo |
| . . .===..o |
| + .Eo+.oo |
| o ..o.+. |
| . .S + . |
| . . . * |
| . . . + o . |
| o O . |
| .*Xo= |
+----[SHA256]-----+COPIAR LA CLAVE PÚBLICA AL SERVIDOR
Una vez generado el par de claves en la máquina local hay que copiar la clave pública al servidor remoto. Esto lo podemos realizar de dos formas
CON SCP
user@localmachine$ scp ~/.ssh/id_rsa.pub user@remotemachine:/home/user/uploaded_key.pubLa clave pública hay que incluirla en el archivo /home/user/.ssh/authorized_keys. Si la carpeta .ssh no existe, la creamos antes de copiar, así como el archivo authorized_keys:
user@remotemachine$ mkdir .ssh
user@remotemachine$ chmod 700 .ssh
user@remotemachine$ touch .ssh/authorized_keys
user@remotemachine$ chmod 600 .ssh/authorized_keysPor último copiamos la clave y borramos el archivo copiado al servidor:
user@remotemachine$ echo `cat ~/uploaded_key.pub` >> ~/.ssh/authorized_keys
user@remotemachine$ rm /home/user/uploaded_key.pubUSANDO SSH-COPY-ID
user@localmachine$ssh-copy-id -i ~/.ssh/id_rsa.pub user@remotemachine
user@remotemachine$ password:
Now try logging into the machine, with "ssh 'remote-host'", and check in:
.ssh/authorized_keysDESHABILITAR EL ACCESO AL SERVIDOR CON CONTRASEÑA
Una vez habilitado el acceso SSH mendiante clave pública, se puede deshabilitar el acceso con contraseña. Esto aumentará la seguridad, pero implica que si se pierde la clave privada se perderá el acceso al servidor: hay que guardar cuidadosamente la clave privada.
La configuración del servidor SSH se puede encontrar en el archivo /etc/ssh/sshd_config. Para deshabilitar el acceso SSH con contraseña hay que añadir la siguiente línea, editando el archivo como root:
PasswordAuthentication noPara aumentar la seguridad se pueden hacer dos ajustes adicionales en el archivo /etc/ssh/sshd_config:
Desactivar el acceso ssh para el usuario root:
PermitRootLogin noDar acceso SSH solo a los usuarios que lo necesiten, y no a todos:
AllowUsers usuario1 usuario2Una vez realizados los cambios, hay que reiniciar el servidor SSH, siempre como root:
service sshd restartACCEDER AL SERVIDOR CON CLAVE PÚBLICA
Para conectarse al servidor con clave pública en vez de contraseña
user@localmachine$ ssh user@remotemachineCómo hacer una copia de seguridad de todo un sistema Linux usando Rsync
Primero, inserta el medio de respaldo (memoria USB o disco duro externo). Luego busca la letra de la unidad con el comando "fdisk -l". o si no está formateado con lsblk por ejemplo /dev/sdb1. Monta la unidad en cualquier lugar de que elijas. Recomendable montarlo bajo /mnt.
mount /dev/sdb1 /mnt
Ahora cuando el dispositivo esté montado
rsync -aAXv / --exclude={"/dev/*","/proc/*","/sys/*","/tmp/*","/run/*","/mnt/*","/media/*","/lost+found"} /mnt
Esto permite copiar sólo archivos, excluyendo los siguientes
dev (dispositivos)
proc (procesos)
sys (sistema)
tmp (temporales)
run
mnt (Especialmente esta, porque de lo contrario se metería en un bucle infinito)
lost+found
-aAXv: los archivos se transfieren en modo "archivo", lo que garantiza que se conservan los enlaces simbólicos, dispositivos, permisos, propiedades, tiempos de modificación, ACL y atributos extendidos.
Configurar Interfaz pppoe Linux
Algunos dispositivos Ethernet como los routers de Movistar funcionan con el protocolo PPPOE (punto a punto sobre Ethernet: «Point to Point Protocol Over Ethernet»). La herramienta pppoeconf (del paquete con el mismo nombre) configurará la conexión
Para hacerlo, modifica el archivo /etc/ppp/peers/dsl-provider con las configuraciones provistas y almacena la información de inicio de sesión en los archivos /etc/ppp/pap-secrets y /etc/ppp/chap-secrets
Las conexiones PPP sobre ADSL son conexiones on-demand, es decir no están permanentemente conectadas.
Ahora veremos la configuración de Linux para usar la conexión de Movistar
apt-get install vlan pppoeconf
Agregaremos el soporte de VLAN
su -c 'echo "8021q" >> /etc/modules'
Supongamos que nuestra red local está en la IP 192.168.1.1 en el archivo /etc/network/interfaces
# The primary network interface allow-hotplug ens18 iface ens18 inet static address 192.168.1.124
Editaremos el archivo para agregar la VLAN de movistar
nano /etc/network/interfaces
allow-hotplug ens18 ens19.6 iface ens18 inet static address 192.168.1.124 iface ens19.6 inet DHCP
Configuramos pppeo
pppoeconf
Un menú basado en texto te guiará a través de los siguientes pasos, que son:
Confirma que se detecte la tarjeta Ethernet.
Introduce tu nombre de usuario (proporcionado por tu ISP) en este caso adslppp@telefonicanetpa
Introduzca su contraseña (proporcionada por te ISP). en este caso adslppp
Si ya tienes configurada una conexión PPPoE, te preguntará si quieres modificarla.
Te pregunta si desea las opciones 'noauth' y 'defaultroute' y para eliminar 'nodetach'; elige "Sí".
Usar DNS del mismo nivel: elige "Sí".
Problema de MSS limitado: elige"Sí".
Cuando tepregunte si desea conectarse al inicio, probablemente querrá decir que sí. (Esta opción no funciona) asi que debemos de realizar cambios en los servicios
Finalmente te pregunta si desea establecer la conexión inmediatamente.
Una vez que hayas terminado estos pasos, tu conexión debería estar funcionando.
Para ejecutar al inicio edita el fichero /etc/systemd/system/adsl- connection.service
[Unit] Description=ADSL connection [Service] Type=forking ExecStart=/usr/sbin/pppd call dsl-provider Restart=always [Install] WantedBy=multi-user.target
Ahora se habilita con
systemctl enable adsl-connection
ip route add default via 192.168.1.1
Configurar Interfaz Wifi Linux
auto wlp1s0 iface wlp1s0 inet dhcp wpa-ssid Ateinco wpa-psk ccb290fd4fe6b22935cbae31449e050edd02ad44627b16ce0151668f5f53c01b
El parámetro wpa-psk puede contener bien la frase de contraseña o su versión con hash generada con el comando wpa_passphrase. La sintaxis del comando es:
wpa_passphrase [ ssid ] [ passphrase ]
wpa_passphrase Ateinco contraseña
Configurar iptables
Para configurar iptables, vamos a instalar un paquete que nos permite salvar nuestra configuración de iptables
apt-get install iptables-persistent iptables-save > /etc/iptables/rules.v4 ip6tables-save > /etc/iptables/rules.v6
Comandos iptables
Permitir http/https
iptables -A INPUT -p tcp -m tcp -m multiport --dports 80,443 -j ACCEPT
Permitir ssh desde algunas ip, denegar del resto
iptables -A INPUT -p tcp -s a.b.c.d --dport 22 -j ACCEPT iptables -A INPUT -p tcp -s e.f.g.0/24 --dport 22 -j ACCEPT iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
Configurar la zona horaria en Linux
Dependiendo de la distribución de Linux, la configuración será la siguiente
Debian / Ubuntu
Para configurar la zona horaria en Debian usaremos el comando:
dpkg-reconfigure tzdataAparecerán las siguientes ventanas:
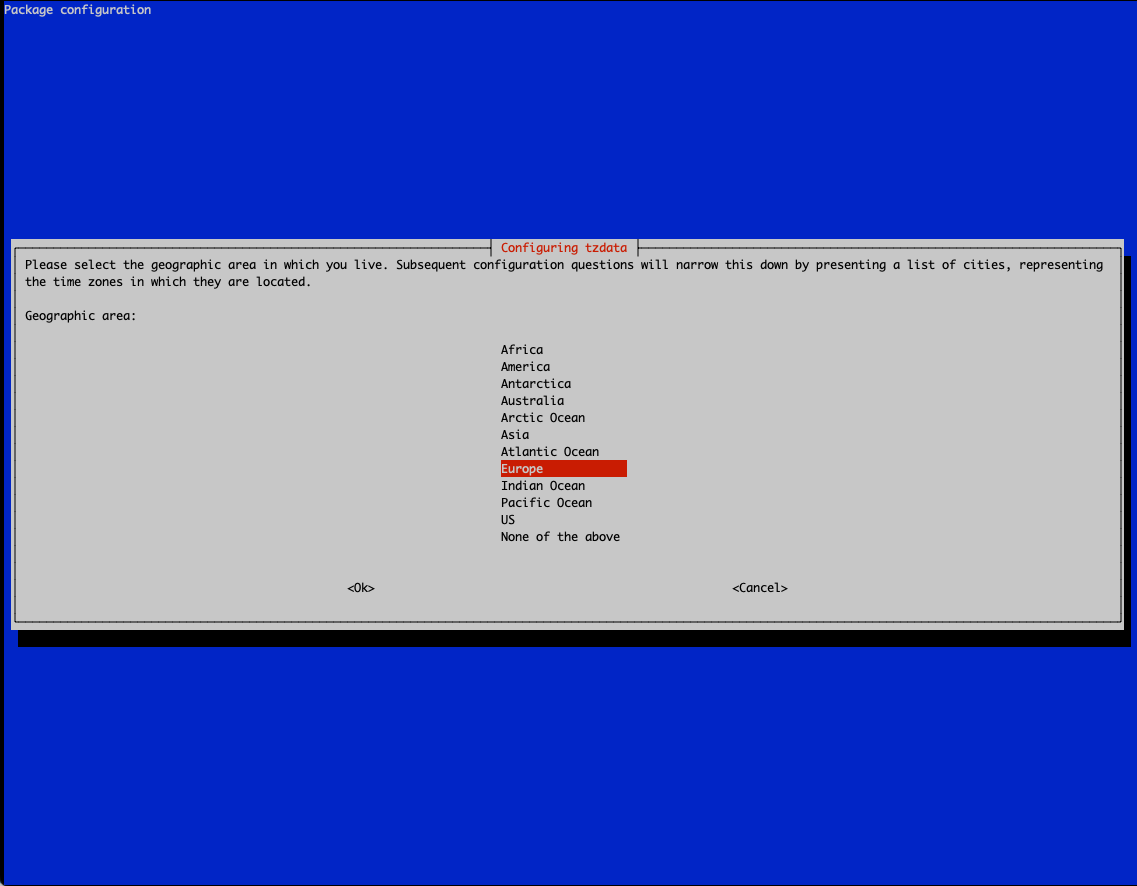
Seleccionamos Europe

Y ya seleccionamos Madrid
Nos aparecerá algo como esto:
Current default time zone: 'Europe/Madrid'
Local time is now: Tue May 17 20:17:18 CEST 2022.
Universal Time is now: Tue May 17 18:17:18 UTC 2022.CentosLa configuración de la zona horaria en Centos se realiza mediante el comando
timedatectl set-timezone Europe/Madrid
Configurar ntp
El NTP es un servicio que si bien en muchas máquinas no es imprescindible, si que es conveniente que en una red, todas las máquinas usen la misma base de tiempo y esté bien sincronizada. No sólo es imprescindible en clusters, también para la revisión de logs, y saber lo que está pasando en nuestra red, es muy conveniente tener la misma hora en todas.
Instalamos y configuramos el servicio NTP
apt-get -y install ntp apt-get -y install ntpdate service ntp restart systemctl enable ntp
Ahora configuramos la zona horaria
Esto podemos realizarlo de dos formas:
cp /usr/share/zoneinfo/Europe/Madrid /etc/localtime
O bien con el comando
dpkg-reconfigure tzdata
Ahora podemos editar el fichero /etc/ntp.conf, para comprobar la configuración
nano /etc/ntp.conf
El fichero tiene el siguiente contenido. La parte #server ntp.your-provider.example es en la que añadimos a la configuración en nuestro caso dos servidores hora.roa.es y hora.rediris.es Los pools, (# pool: <http://www.pool.ntp.org/join.html>) los podemos modificar a nuestra voluntad, bien con servidores o con pools de NTP
# /etc/ntp.conf, configuration for ntpd; see ntp.conf(5) for help driftfile /var/lib/ntp/ntp.drift # Enable this if you want statistics to be logged. #statsdir /var/log/ntpstats/ statistics loopstats peerstats clockstats filegen loopstats file loopstats type day enable filegen peerstats file peerstats type day enable filegen clockstats file clockstats type day enable # You do need to talk to an NTP server or two (or three). #server ntp.your-provider.example ################################################################## ## Agregamos nuestros servidores NTP Por lo general es recomendable usar los de RedIris ## hora.roa.es y hora.rediris.es ################################################################## server hora.roa.es server hora.rediris.es # pool.ntp.org maps to about 1000 low-stratum NTP servers. Your server will # pick a different set every time it starts up. Please consider joining the # pool: <http://www.pool.ntp.org/join.html> pool 0.debian.pool.ntp.org iburst pool 1.debian.pool.ntp.org iburst pool 2.debian.pool.ntp.org iburst pool 3.debian.pool.ntp.org iburst # Access control configuration; see /usr/share/doc/ntp-doc/html/accopt.html for # details. The web page <http://support.ntp.org/bin/view/Support/AccessRestrictions> # might also be helpful. # # Note that "restrict" applies to both servers and clients, so a configuration # that might be intended to block requests from certain clients could also end # up blocking replies from your own upstream servers. # By default, exchange time with everybody, but don't allow configuration. restrict -4 default kod notrap nomodify nopeer noquery limited restrict -6 default kod notrap nomodify nopeer noquery limited # Local users may interrogate the ntp server more closely. restrict 127.0.0.1
Iniciamos el servicio NTP
service ntp restart
Y configuramos el servicio para que se inicie al arrancar la máquina
systemctl enable ntp
Verificar la sincronización del servidor
Para verificar si tras el reinicicio del proceso ntp nuestro servidor NTP está sincronizando su hora local con el pool de servidores NTP de Internet, ejecutaremos el siguiente comando:
ntpq -p
Nos dará un resultado parecido a este:
root@mail:~# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
0.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
1.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
2.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
3.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
ntp.ubuntu.com .POOL. 16 p - 64 0 0.000 0.000 0.000
hora.roa.es .INIT. 16 u - 64 0 0.000 0.000 0.000
hora.rediris.es .INIT. 16 u - 64 0 0.000 0.000 0.000
Las columnas indican lo siguiente:
- remote - Indica los servidores de ntp definidos en el fichero ntp.conf. '*' indica que es el servidor actual y el mejor origen de sincronización
- '+' indica que son servidores disponibles de NTP. Los orígenes con - son considerados como no usables.
- refid - La dirección IP del servidor NTP del cual se obtiene la hora.
- st - Stratum
- t - Tipo. 'u' para unicast. Existen otros valores como por ejemplo local, multicast, broadcast...
- when - Tiempo transcurrido (en segundos) desde el último contacto con el servidor NTP.
- poll - Frecuencia de sondeo con el servidor en segundos.
- reach - Un valor en octal que indica cuando hay algún tipo de error en la comunicación con el servidor. El valor 377 indica 100% de éxitos.
- delay - El 'round trip' entre nuestro servidor y el servidor remoto.
- offset - La diferencia de tiempo entre nuestro equipo local y el equipo remoto en milisegundos.
- jitter - La media de tiempos en milisegundos entre dos muestras.
Problemas con el servicio NTP
A veces hay problemas con el inicio del servicio NTP por ejemplo ene Ubuntu 18.04 LTS. Está habilitado, pero inactivo, así que hay que iniciarlo manualmente después de cada reinicio.
systemctl status ntp.service
● ntp.service - Network Time Service
Loaded: loaded (/lib/systemd/system/ntp.service; enabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:ntpd(8)
La razón está en un conflicto con el servicio systemd-timesyncd.service, que es parte de systemd. Después de deshabilitarlo, ntp.service arrancará sin problemas.
systemctl show ntp.service | grep Conflicts Conflicts=shutdown.target systemd-timesyncd.service
systemctl status systemd-timesyncd.service ● systemd-timesyncd.service - Network Time Synchronization Loaded: loaded (/lib/systemd/system/systemd-timesyncd.service; enabled; vendor preset: enabled) Active: active (running) since Fri 2019-07-12 05:17:21 UTC; 18min ago
Para deshabilitarlo bastará con ejecutar
systemctl disable systemd-timesyncd.service
Configurar un servidor FTP con vsftpd
Ejecutaremos la actualización del sistema
apt update && apt upgrade
Una vez esté todo actualizado procederemos a instalar el paquete vsftpd
sudo apt install vsftpd
Con eso termina todo lo que hay que instalar, ahora tendríamos que tocar el fichero /etc/vsftpd.conf y modificar las líneas:
listen=YES .. write_enable=YES .. #connect_from_port_20=YES listen_port=21
Y luego habilitar el chroot
chroot_local_user=YES chroot_list_enable=YES chroot_list_file=/etc/vsftpd.chroot_list
En este punto tendremos que editar el fichero /etc/vsftpd.chroot_list y añadir ahí los usuarios a los que quedamos dejar excluidos del chroot, si es que queremos dejar excluídos a alguno.
Fail2ban
Instalación de Fail2ban
Eliminar IP de ls lista de IP Baneadas. Para ello ejecutamos el siguiente comando:
fail2ban-client -i
Cuando lo ejecutemos, aparecerá el prompt de la consola de comandos de fail2ban
root@mail:~# fail2ban-client -i Fail2Ban v0.9.6 reads log file that contains password failure report and bans the corresponding IP addresses using firewall rules. fail2ban>
En la consola, ejecutamos status y el jail que queremos desbloquear, o del que queremos averiguar las IP bloqueadas
fail2ban> status sshd Status for the jail: sshd |- Filter | |- Currently failed: 0 | |- Total failed: 3 | `- File list: /var/log/auth.log `- Actions |- Currently banned: 0 |- Total banned: 1 `- Banned IP list: 1.2.3.4
set sshd unbanip 1.2.3.4
Devolverá 1.2.3.4
Para salir de la línea de comando, teclearemos exit.
Ipmi linux
Como instalar IPMI en debian: IPMI (Intelligent Platform Management Interface), es un conjunto de especificaciones de interfaz para un subsistema autónomo que proporciona capacidades de administración y monitorización independientemente de la CPU, el firmware (BIOS o UEFI) y el sistema operativo del sistema host. IPMI define un conjunto de interfaces que utilizan los administradores de sistemas para la gestión fuera de banda (out of band) de los sistemas informáticos y el seguimiento de su funcionamiento. Por ejemplo, IPMI proporciona una forma de administrar una equipo que puede estar apagado o no responder mediante el uso de una conexión de red al hardware en lugar de a un sistema operativo o shell de inicio de sesión. Otro caso de uso puede ser instalar un sistema operativo personalizado de forma remota. Sin IPMI, la instalación de un sistema operativo personalizado puede requerir que un administrador esté físicamente presente cerca del equipo, inserte un DVD o una unidad flash USB que contenga el instalador del sistema operativo y complete el proceso de instalación usando un monitor y un teclado. Con IPMI, un administrador puede montar una imagen ISO, simular un DVD de instalación y realizar la instalación de forma remota.
Para instalar esta característica en debian ejecutaremos:
apt install ipmitool
Para comprobar el funcionamiento por ejemplo en un sistema DELL IDRAC
/usr/bin/ipmitool -I lanplus -c -H a.b.c.d -U 'root' -P 'calvin' -L USER sdr 2>/dev/null
Donde a.b.c.d es la IP IDRAC del equipo, con usuario root y password calvin (las credenciales por defecto del DELL)
Kill
Comando para matar todos los procesos segúnun criterio. Por ejemplo matar todos los procesos Sogo de un servidor.
for pid in $(ps -ef | grep "sogo" | awk '{print $2}'); do kill -9 $pid; done
Listar archivos grandes linux
La forma de buscar archivos con un tamaño superior a un valor determinado.
Por ejemplo para buscar archivos de más de 100Mb y listarlos.
find . -xdev -type f -size +100M -exec ls -la {} \; | sort -nk 5
Si solo queremas saber la ubicación sin conocer el tamaño exacto de cada uno:
find . -xdev -type f -size +100M
Procesos Linux ps
Comando ps
El comando ps, se utiliza para enumerar los procesos que se están ejecutando actualmente y sus PID en sistemas Linux y similares a Unix. Al ejecutarlo nos dará al menos dos procesos.
root@server02:~# ps PID TTY TIME CMD 15530 pts/0 00:00:00 ps 22082 pts/0 00:00:00 bash
Modificadores
Mostrar todos los procesos
Por defecto, ps muestra sólo los procesos que se ejecutaron desde su propia terminal (xterm, acceso en modo texto o acceso remoto). Las opciones -A y -e hacen que se muestren todos los procesos del sistema y x muestra todos los procesos que pertenecen al usuario que proporciona el comando. La opción xtambién incrementa la cantidad de información que se muestra sobre cada proceso.
ps -A
root@nms:~# ps -A
PID TTY TIME CMD
1 ? 00:00:34 systemd
2 ? 00:00:00 kthreadd
3 ? 00:00:00 rcu_gp
4 ? 00:00:00 rcu_par_gp
6 ? 00:00:00 kworker/0:0H-kblockd
8 ? 00:00:00 mm_percpu_wq
9 ? 00:01:48 ksoftirqd/0
10 ? 00:01:23 rcu_sched
11 ? 00:00:00 rcu_bh
12 ? 00:00:08 migration/0 .......
Mostrar los procesos de un usuario
Puede mostrar los procesos que pertenecen a un usuario concreto con las opciones -u usuario, U usuario, y --User usuario. La variable usuario puede ser un nombre de usuario o el ID de usuario
ps -u
root@nms:~# ps -u eduardo
Mostrar información adicional.
Las opciones -f, -l, j, l, u y v amplían la información proporcionada en la salida de ps. La mayoría de los formatos de ps incluye una línea por proceso, pero ps puede mostrar tanta información que es imposible adaptarla a una salida con líneas de 80 caracteres. Por este motivo, estas opciones ofrecen varias combinaciones para la salida.
ps -f
root@nms:~# ps -f UID PID PPID C STIME TTY TIME CMD root 3129 3088 0 08:00 pts/0 00:00:00 -bash root 4931 3129 0 08:04 pts/0 00:00:00 ps -f
ps -l
root@nms:~# ps -l F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD 4 S 0 3129 3088 0 80 0 - 1979 - pts/0 00:00:00 bash 0 R 0 7803 3129 0 80 0 - 2637 - pts/0 00:00:00 ps
ps j
root@nms:~# ps j
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
1 400 400 400 tty1 400 Ss+ 0 0:00 /sbin/agetty -o -p -- \u --noclear tty1 linux
3088 3129 3129 3129 pts/0 7805 Ss 0 0:00 -bash
3129 7805 7805 3129 pts/0 7805 R+ 0 0:00 ps j
ps l
root@nms:~# ps l F UID PID PPID PRI NI VSZ RSS WCHAN STAT TTY TIME COMMAND 4 0 400 1 20 0 5612 1512 core_s Ss+ tty1 0:00 /sbin/agetty -o -p -- \u --noclear tty1 linux 4 0 3129 3088 20 0 7916 4532 - Ss pts/0 0:00 -bash 0 0 7809 3129 20 0 10548 1272 - R+ pts/0 0:00 ps l
ps u[editar | editar código]
root@nms:~# ps u USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 400 0.0 0.0 5612 1512 tty1 Ss+ nov08 0:00 /sbin/agetty -o -p -- \u --noclear tty1 linux root 3129 0.0 0.0 7916 4532 pts/0 Ss 08:00 0:00 -bash root 7811 0.0 0.0 10632 3008 pts/0 R+ 08:07 0:00 ps u
ps v
root@nms:~# ps v PID TTY STAT TIME MAJFL TRS DRS RSS %MEM COMMAND 400 tty1 Ss+ 0:00 2 42 5569 1512 0.0 /sbin/agetty -o -p -- \u --noclear tty1 linux 3129 pts/0 Ss 0:00 0 873 7042 4532 0.0 -bash 7868 pts/0 R+ 0:00 0 108 10439 1276 0.0 ps v
Mostrar la jerarquía de procesos
Las opciones -H, -f y --forest agrupan los procesos y emplean sangrías para mostrar la jerarquía de las relaciones entre los procesos. Estas opciones le serán útiles si intenta averiguar los parentescos de un proceso.
Mostrar la salida a todo el ancho
La salida del comando ps puede ser superior a las 80 columnas. Normalmente, ps trunca su salida para que se adapte a su pantalla o xterm. Las opciones -w y w le indican a ps que no haga esto, esto nos puede ser útil si dirigimos la salida a un fichero, como en ps w > ps.txt. Después, podemos examinar tranquilamente el fichero de salida en un editor de texto que admita líneas anchas.
Comandos útiles
Mostrar todos los procesos con el ID de proceso y el predecesor
ps -ef
root@nms:~# ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 nov08 ? 00:00:35 /sbin/init root 2 0 0 nov08 ? 00:00:00 [kthreadd] root 3 2 0 nov08 ? 00:00:00 [rcu_gp] root 4 2 0 nov08 ? 00:00:00 [rcu_par_gp] root 6 2 0 nov08 ? 00:00:00 [kworker/0:0H-kblockd] root 8 2 0 nov08 ? 00:00:00 [mm_percpu_wq] root 9 2 0 nov08 ? 00:01:48 [ksoftirqd/0]
Filtrar
El comando ps con la concatenación del comando grep, permite buscar un proceso
ps -ef | grep texto-a-buscar
root@nms:~# ps -ef | grep php root 381 1 0 nov08 ? 00:00:19 php-fpm: master process (/etc/php/7.3/fpm/php-fpm.conf) www-data 16057 381 0 nov11 ? 00:00:11 php-fpm: pool www www-data 16292 381 0 nov11 ? 00:00:10 php-fpm: pool www root 16533 3129 0 08:24 pts/0 00:00:00 grep php www-data 18178 381 0 nov11 ? 00:00:08 php-fpm: pool www
Número de procesos
Con la concatenación del comando wc -l, permite contar los procesos
root@nms:~# ps -ef | wc -l 201
Como en cualquier comando linux se permite la concatenación múltiple
root@nms:~# ps -ef | grep php | wc -l 5
Redimensionar un disco en Linux
Muchas veces vemos que hemos cometido errores a la hora de dimensionar el disco en una máquina Linux, esto plantea que hay que cambiar el tamaño de disco, pero Linux, deja la partición swap al final de las particiones de datos, por lo que hay que seguir un pequeño procedimiento para realizar el proceso.
Eliminar la partición swap
Primero averiguamos cual es la partición swap, para ello, ejecutamos
cat /proc/swaps
Para eliminar la partición swap realizamos un swapoff
swapoff /dev/sdx
Elimina la entrada de swap del fichero /etc/fstab.
Elimina la partición (esta ya se puede hacer desde comando o bien desde el Gparted u otra herramienta.
Redimensionar disco
Para esto podemos utilizar el manual de Gparted https://gparted.org/display-doc.php?name=help-manual&lang=es
Volver a crear partición swap
Suponiendo que nuestro disco de swap es el /dev/vda5
mkswap /dev/vda5
Guardamos el UUID que estará en /dev/disk/by-uuid Ejecutamos
swapon /dev/vda5
Recolocar todo
Ahora hay que editar el fstab para asignar al swap el UUID de la partición swap
Editamos el fichero /etc/fstab. Habrá a lo mejor una entrada de swap
UUID=61faa4de-9caf-4837-ae8e-xxxxxxxxxx none swap defaults 0 0
Sustituiremos el UUID por el que nos ha generado nuestra nueva partición swap
Además deberemos de modificar el fichero de resume de initramfs que se encuentra en:
/etc/initramfs-tools/conf.d
Lo editamos
Cambiamos el UUID y ejecutamos
update-initramfs -u
Rearrancamos y realizamos un systemd-analyze para ver el tiempo de arranque
rsync
Uso de rsync
rsync es la herramienta de copiado y sincronización de archivos más potente que existe en el mundo de Linux, es rápida, versatil para el copiado local y remoto de archivos. Ofrece una larga lista de opciones que controlan todos los posibles aspectos de su comportamiento.
El 'secreto' de rsync es su algoritmo llamado 'delta-transfer' que reduce la cantidad de datos que se envían vía red al enviar solo las diferencias que hay entre dos archivos a nivel de sus metadatos (permisos, fechas de acceso, etc) y del contenido de sus datos a nivel de bloques en disco.
Sintaxis
El modo de uso de rsync es idéntica a los comandos cp o scp, es decir, rsync [opciones] origen [destino]
El 'destino' en rsync se dice que es opcional porque si solo se usa el origen, entonces equivale a listar el directorio o archivo origen.
Tanto el 'origen' como el 'destino' pueden ser locales o remotos
Opciones
| Opción | Descripción | |
|---|---|---|
| Corta | Larga | |
| -a | --archive | Modo archive, es igual a indicar las opciones r,l,p,t,g,o y D |
| -r | --recursive | Recursivo, copia recursivamente los directorios. |
| -l | --links | Cuando encuentra symlinks (enlaces simbólicos), estos son recreados en el destino. |
| -p | --perms | Opción que causa en el destino establecer los permisos igual que en el origen. |
| -t | --times | Transfiere los tiempos de los archivos (atime, ctime, mtime) al destino |
| -g | --group | Establece en el destino que el grupo del archivo copiado sea igual que el origen. |
| -o | --owner | Establece en el destino que el propietario del archivo copiado sea igual que el origen. |
| -D | Esto es igual que indicar las opciones --devices y --specials | |
| --exclude PATTERN | Excluye archivos que igualan el patrón o pattern indicado. | |
| --include PATTERN | Incluye archivos que igualan el patrón o pattern indicado. | |
| --devices | Transfiere archivos de dispositivos de bloque y caracter al destino donde son recreados. Esto solo puede suceder si en el destino se tienen permisos de root. | |
| --specials | Transfiere archivos especiales como fifos y named sockets. | |
| --version | Indica el número de versión de rsync |
|
| -v | --verbose | Incrementa la cantidad de información que se informa durante la transferencia o copia de archivos. Es la opción contraria a --quiet |
| -q | --quiet | Decremente la cantidad de información que se informa durante la transferecnia o copia de archivos. Generalmente se utiliza cuando rsync se utiliza en una tarea cron. Es la opción contraria a --verbose |
| -I | --ignore-times | Una de las grandes virtudes de rsync es que al momento de copiar o transferir archivos, si estos son iguales en el destino en términos de tiempos y tamaño ya no lo copia, no hay cambios. Esta opción permite que esto sea ignorado y todos los archivos serán copiados/actualizados en el destino. (ver --size-only también) |
| --size-only | Normalmente solo se transfieren archivos con los tiempos cambiados o el tamaño cambiado. Con esta opción se ignoran los tiempos de los archivos y se transfiere cualquiera con un tamaño distinto en el destino. | |
| -n | --dry-run | Crea una prueba de test de lo que realmente ocurrirá sin esta opción, sin realizar ningún cambio. Es decir, la salida mostrada será muy similar a lo que realmente pasará si no se incluye --dry-run. Generalmente se usa junto con la opción --verbose y la opción --itemize-changes |
| -i | --itemize-changes | Reporta una lista de los cambios realizados en cada archivo, incluidos cambios en sus atributos. Esto es equivalente a utilizar -vv en versiones obsolteas de rsync. |
| --remove-source-files | Remueve los archivos en el origen (no directorios) si en el destino estos fueron exitosamente duplicados o copiados. | |
| --timeout=TIEMPO | Especifica un timeout en segundos, si no datos son transferidos en tiempo indicado rsync terminará. El default es 0 segundos que quiere decir sin timeout. |
|
| --log-file=ARCHIVO | Bitacoriza lo que se ha realizado en el ARCHIVO indicado. | |
| --stats | Imprime un conjunto informativo de datos estadísticos sobre la transferencia realizada. | |
| --progress | Muestra el avance o progreso de los archivos que están siendo transferidos. | |
| --bwlimit=KBPS | Permite establecer un límite de transferencia en kilobytes por segundo. Esta opción su default es 0, lo que indica no límite en el uso del ancho de banda en la transferencia. | |
| --max-size=TAMAÑO | No transfiere cualquier archivo más grande que el TAMAÑO indicado. | |
| --min-size=TAMAÑO | No transfiere cualquier archivo más pequeño que el TAMAÑO indicado. | |
| -z | --compress | Comprimir datos durante la transferencia. |
Ejemplos
Sincronizar entre dos carpetas
rsync -avP /carpeta1/* /carpeta2/.
Sincronizar entre hosts
rsync -avP root@w.x.y.z:/carpeta1/* /carpeta2/.
Transferir archivos de determinado tamaño
rsync -avzhP --max-size='100M' /carpeta1 root@w.x.y.z:/carpeta2/
En esta caso sólo se copiarán los archivos menores de 100 Mb
Sincronizar archivos completamente entre dos carpetas o servidores
Esto permite actualizar archivos en destino, y si no existen en origen, los borra
rsync -avhP origen/ destino/ --delete-after
Uso de atop
Breve manual del uso de atop.
En primer lugar instalamos atop
apt-get install atop
A continuación, iniciamos el servicio atop para comenzar el registro automático de recursos del sistema:
service atop start
Nota: atop crea automáticamente una tarea en cron para comenzar a registrar a medianoche si no se está ejecutando.
Abreel archivo /etc/init.d/atop(o /etc/default/atop, o /usr/share/atop/atop.daily) y modifica la línea y establece el intervalo requerido (en segundos):
INTERVAL=60
Los datos registrados se pueden abrir mediante el comando:
atop -r /var/log/atop/atop_*****
Donde *** es el valor de registro real (fecha). Para moverse entre los intervalos puedes usar las flechas del teclado o teclas de acceso rápido t y Shift + T .
Para deshabilitar atop, usa los siguientes comandos:
mv /etc/cron.d/atop /root/atop service atop stop
Ejemplo de un registro de atop
ATOP - trafico 2021/04/03 08:08:59 -------------- 125d22h10m44s elapsed
PRC | sys 9m56s | user 4m21s | | | #proc 31 | #trun 3 | #tslpi 82 | #tslpu 0 | #zombie 0 | clones 106e6 | | | no procacct |
CPU | sys 0% | user 0% | irq 0% | | idle 200% | wait 0% | steal 0% | guest 0% | | ipc notavail | cycl unknown | curf 1.94GHz | curscal ?% |
cpu | sys 0% | user 0% | irq 0% | | idle 100% | cpu000 w 0% | steal 0% | guest 0% | | ipc notavail | cycl unknown | curf 2.28GHz | curscal ?% |
cpu | sys 0% | user 0% | irq 0% | | idle 100% | cpu001 w 0% | steal 0% | guest 0% | | ipc notavail | cycl unknown | curf 1.60GHz | curscal ?% |
CPL | avg1 1.81 | | avg5 2.19 | avg15 2.47 | | | csw 281818e6 | | intr 12095e7 | | | numcpu 2 | |
MEM | tot 1.0G | free 773.8M | cache 162.1M | dirty 0.8M | buff 0.0M | slab 0.0M | slrec 0.0M | shmem 32.2M | shrss 0.0M | shswp 0.0M | vmbal 0.0M | hptot 0.0M | hpuse 0.0M |
SWP | tot 1.0G | free 1.0G | | | | | | | | | vmcom 108.2G | | vmlim 102.4G |
PAG | scan 11390e5 | steal 1134e6 | | stall 0 | | | | | | | swin 364324 | | swout 3307e3 |
PSI | cs 2/0/0 | | ms 0/0/0 | mf 0/0/0 | | is 1/1/1 | if 1/1/1 | | | | | | |
LVM | dm-2 | busy 19% | | read 33427e4 | write 1254e6 | KiB/r 44 | KiB/w 9 | | MBr/s 1.3 | MBw/s 1.1 | avq 1.28 | | avio 1.32 ms |
LVM | dm-0 | busy 17% | | read 38284e4 | write 1658e6 | KiB/r 45 | KiB/w 10 | | MBr/s 1.5 | MBw/s 1.5 | avq 0.93 | | avio 0.96 ms |
LVM | dm-1 | busy 16% | | read 30503e4 | write 1624e6 | KiB/r 46 | KiB/w 12 | | MBr/s 1.3 | MBw/s 1.8 | avq 0.87 | | avio 0.96 ms |
LVM | dm-3 | busy 15% | | read 47981e4 | write 1571e6 | KiB/r 44 | KiB/w 9 | | MBr/s 1.9 | MBw/s 1.4 | avq 1.12 | | avio 0.85 ms |
LVM | dm-5 | busy 2% | | read 172160 | write 1581e5 | KiB/r 43 | KiB/w 20 | | MBr/s 0.0 | MBw/s 0.3 | avq 3.19 | | avio 1.76 ms |
LVM | dm-8 | busy 0% | | read 62887 | write 7744e3 | KiB/r 21 | KiB/w 12 | | MBr/s 0.0 | MBw/s 0.0 | avq 6.98 | | avio 1.83 ms |
LVM | dm-7 | busy 0% | | read 62887 | write 7744e3 | KiB/r 21 | KiB/w 12 | | MBr/s 0.0 | MBw/s 0.0 | avq 6.99 | | avio 1.83 ms |
LVM | dm-11 | busy 0% | | read 53327 | write 7526e3 | KiB/r 21 | KiB/w 11 | | MBr/s 0.0 | MBw/s 0.0 | avq 34.12 | | avio 1.84 ms |
LVM | dm-4 | busy 0% | | read 364470 | write 3307e3 | KiB/r 4 | KiB/w 4 | | MBr/s 0.0 | MBw/s 0.0 | avq 38.28 | | avio 0.38 ms |
LVM | dm-10 | busy 0% | | read 10825 | write 315635 | KiB/r 24 | KiB/w 17 | | MBr/s 0.0 | MBw/s 0.0 | avq 21.30 | | avio 1.46 ms |
LVM | dm-6 | busy 0% | | read 3674 | write 28208 | KiB/r 4 | KiB/w 4 | | MBr/s 0.0 | MBw/s 0.0 | avq 3.43 | | avio 2.35 ms |
DSK | sdc | busy 19% | | read 19903e4 | write 1241e6 | KiB/r 76 | KiB/w 9 | | MBr/s 1.4 | MBw/s 1.1 | avq 0.43 | | avio 1.46 ms |
DSK | sde | busy 17% | | read 23129e4 | write 1617e6 | KiB/r 75 | KiB/w 10 | | MBr/s 1.6 | MBw/s 1.5 | avq 0.22 | | avio 1.06 ms |
DSK | sdd | busy 16% | | read 17500e4 | write 1525e6 | KiB/r 83 | KiB/w 13 | | MBr/s 1.3 | MBw/s 1.8 | avq 0.19 | | avio 1.08 ms |
DSK | sdb | busy 15% | | read 29484e4 | write 1553e6 | KiB/r 73 | KiB/w 9 | | MBr/s 1.9 | MBw/s 1.4 | avq 0.30 | | avio 0.94 ms |
DSK | sda | busy 3% | | read 6869731 | write 8765e4 | KiB/r 122 | KiB/w 39 | | MBr/s 0.1 | MBw/s 0.3 | avq 2.27 | | avio 3.25 ms |
NET | transport | tcpi 635685 | tcpo 614339 | udpi 225373 | udpo 225392 | tcpao 7 | tcppo 3 | | tcprs 1994 | tcpie 0 | tcpor 106 | udpnp 61 | udpie 0 |
NET | network | ipi 2479166 | | ipo 846467 | ipfrw 0 | deliv 1021e3 | | | | | icmpi 7 | | icmpo 949 |
NET | eth0 0% | pcki 34036e3 | pcko 860356 | sp 10 Gbps | si 2 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 13567 | drpo 0 |
NET | eth1 0% | pcki 51588 | pcko 315 | sp 10 Gbps | si 0 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
NET | eth2 0% | pcki 303 | pcko 417 | sp 10 Gbps | si 0 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
NET | lo ---- | pcki 7394 | pcko 7394 | sp 0 Mbps | si 0 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
*** system and process activity since boot ***
PID SYSCPU USRCPU VGROW RGROW RDDSK WRDSK RUID EUID ST EXC THR S CPUNR CPU CMD 1/1
145 8m15s 3m17s 29608K 11860K 7336K 4K Debian-s Debian-s N- - 1 S 7 0% snmpd
166643 44.69s 26.22s 12820K 6192K 60K 0K root root N- - 1 S 18 0% ssh
195 31.93s 16.15s 8432K 4928K 4K 108K root root N- - 1 S 7 0% apache2
51 10.75s 6.73s 83804K 60680K 280K 0K root root N- - 1 S 7 0% systemd-journa
92 1.79s 5.95s 9108K 4036K 1256K 0K messageb messageb N- - 1 R 7 0% dbus-daemon
1 2.60s 4.22s 166.5M 10140K 98.2M 14432K root root N- - 1 R 7 0% systemd
373 3.03s 1.13s 43472K 3784K 360K 8K root root N- - 1 S 7 0% master
94 3.10s 0.70s 5508K 2240K 14820K 18.0G root root N- - 1 S 7 0% cron
91 1.59s 1.14s 152.5M 4096K 1280K 48616K root root N- - 3 S 18 0% rsyslogd
90 0.66s 1.03s 19512K 7276K 232K 0K root root N- - 1 S 7 0% systemd-logind
376 0.59s 0.25s 43864K 6912K 132K 0K postfix postfix N- - 1 S 7 0% qmgr
261385 0.07s 0.67s 61968K 53332K 13404K 1080K root root N- - 1 S 7 0% apt
261531 0.06s 0.00s 10996K 4436K 164K 0K root root N- - 1 R 18 0% atop
382 0.03s 0.03s 4656K 3668K 88944K 100.7M root root N- - 1 S 18 0% bash
261370 0.01s 0.02s 16900K 8248K 12K 0K root root N- - 1 S 18 0% sshd
151 0.01s 0.02s 6920K 3024K 852K 8K root root N- - 1 S 18 0% login
261373 0.02s 0.00s 21024K 8324K 140K 0K root root N- - 1 S 18 0% systemd
261382 0.00s 0.02s 4656K 4044K 480K 8K root root N- - 1 S 18 0% bash
260607 0.00s 0.01s 43812K 7080K 0K 0K postfix postfix N- - 1 S 7 0% pickup
261532 0.00s 0.01s 8324K 5236K 0K 0K root root N- - 1 S 18 0% update-rc.d
261419 0.00s 0.01s 9180K 3716K 0K 40K root root N- - 1 S 7 0% dpkg
159 0.00s 0.00s 15848K 6520K 184K 12K root root N- - 1 S 7 0% sshd
254411 0.00s 0.00s 1.2G 3916K 0K 0K www-data www-data N- - 27 S 7 0% apache2
254412 0.00s 0.00s 1.2G 3916K 0K 0K www-data www-data N- - 27 S 7 0% apache2
261374 0.00s 0.00s 166.4M 3296K 0K 0K root root N- - 1 S 7 0% (sd-pam)
261538 0.00s 0.00s 8040K 3272K 0K 0K root root N- - 1 S 18 0% systemctl
261420 0.00s 0.00s 3780K 2928K 480K 8K root root N- - 1 S 18 0% atop.postinst
153 0.00s 0.00s 2416K 1512K 52K 0K root root N- - 1 S 7 0% agetty
152 0.00s 0.00s 2416K 1408K 0K 0K root root N- - 1 S 18 0% agetty
261536 0.00s 0.00s 2292K 752K 40K 0K root root N- - 1 S 7 0% sleep
261535 0.00s 0.00s 3732K 248K 0K 0K root root N- - 1 S 7 0% atop.daily
Usuarios y grupos en Linux
Generalmente se almacena la lista de usuarios en el archivo /etc/passwd y el archivo /etc/shadow almacena las contraseñas con hash. Ambos son archivos de texto en un formato relativamente simple que pueden leerse y modificarse con un editor de texto. Se muestra cada usuario en una línea con varios campos separados por dos puntos.
Lista de usuarios
Se encuentra en el fichero /etc/passwd
Esta es una lista de los campos en el archivo /etc/passwd:
nombre de usuario, por ejemplo etaboada;
contraseña: esta es una contraseña cifrada por una función unidireccional (crypt), que utiliza DES, MD5, SHA-256 o SHA-512. El valor especial «x» indica que la contraseña cifrada está almacenada en /etc/shadow;
uid: número único que identifica a cada usuario;
gid: número único del grupo principal del usuario (de forma predeterminada, Debian crea un grupo específico para cada usuario);
GECOS: campo de datos que generalmente contiene el nombre completo del usuario;
directorio de inicio de sesión, asignado al usuario para almacenar sus archivos personales (al que generalmente apunta la variable de entorno $HOME);
programa a ejecutar al iniciar sesión. Generalmente es un intérprete de órdenes (consola) que le da libertad al usuario. Si especifica /bin/false (que no hace nada y vuelve el control inmediatamente), el usuario no podrá iniciar sesión.
El archivo de contraseñas ocultas y cifradas
Se encuentra en el fichero /etc/shadow
El archivo /etc/shadow contiene los siguientes campos:
nombre de usuario;
contraseña cifrada;
varios campos que administran el vencimiento de la contraseña.
Comandos relacionados con el usuario
passwd
passwd le permite a un usuario normal cambiar su contraseña que, a su vez, actualiza el archivo /etc/shadow
chfn
chfn (cambiar el nombre completo: «CHange Full Name»), reservado para el superusuario (root), modifica el campo GECOS
chsh
(cambiar consola: «CHange SHell») le permite a un usuario cambiar su consola de inicio de sesión; sin embargo las opciones disponibles estarán limitadas a aquellas mencionadas en /etc/shells; el administrador, por el otro lado, no está limitado por esta restricción y puede configurar la consola a cualquier programa de su elección.
chage
chage (cambiar edad: «CHange AGE») permite al administrador cambiar la configuración de expiración de la contraseña (la opción -l usuario mostrará la configuración actual). También puede forzar la expiración de una contraseña utilizando la orden passwd -e usuario, que obligará al usuario a cambiar su contraseña la próxima vez que inicie sesión.
passwd -l usuario
Este comando permite desactivar una cuenta (bloquear el acceso a un usuario). Una cuenta desactivada significa que el usuario no podrá iniciar sesión y obtener acceso a la máquina. La cuenta se mantiene intacta en el equipo y no se eliminarán archivos o datos.
Puedes reactivar la cuenta de forma similar, utilizando la opción -u (desbloquear: «unlock»).
Lista de grupos
Se encuentra en el fichero /etc/group. Una simple base de datos de texto en un formato similar al del archivo /etc/passwd con los siguientes campos:
nombre del grupo;
contraseña (opcional): sólo es utilizada para unirse a un grupo cuando no es un miembro normal
gid: número único de identificación del grupo;
lista de miembros: lista separados por comas de nombres de usuario que son miembros del grupo.
Personalizar bash mediante .bashrc
Colorear los archivos según tipo o atributos
export LS_OPTIONS='--color=auto'
eval "$(dircolors)"
alias ls='ls $LS_OPTIONS'
alias ll='ls $LS_OPTIONS -l'
alias l='ls $LS_OPTIONS -lA'
alias grep='grep --color=auto'
alias fgrep='fgrep --color=auto'
alias egrep='egrep --color=auto'Permisos extendidos de archivos en linux
Existen una serie de permisos especiales que, aunque no son habituales, es necesarios saberlos, por ejemplo, para trabajar en grupo sobre ciertos directorios.
sticky bit
Se trata de un permiso de acceso que puede ser asignado a ficheros y directorios en sistemas UNIX y similares. Aunque históricamente su fin eran otro, actualmente el sticky bit se utiliza sobre directorios.
Cuando se le asigna a un directorio, significa que los elementos que hay en ese directorio solo pueden ser renombrados o borrados por su propietario o bien por root. El resto de usuarios que tengan permisos de lectura y escritura, los podrán leer y modificar, pero no borrar.
Es un atributo muy común en la carpeta /tmp
Para asignar el permiso se usa el modificador t o bien mediante chmod con un 1 al principio.
chmod 1775 /micarpetaO bien
chmod +t /micarpeta #para activar sticky bit
chmod -t /micarpeta #para desactivar sticky bit
Si un usuario intenta borrar un fichero en una carpeta con sticky bit, no podrá.
SUID
Cuando se activa el bit SUID sobre un fichero significa que el que lo ejecute va a tener los mismos permisos que el que creó el archivo. Esto es útil en algunas ocasiones, aunque hay que utilizarlo con cuidado, ya que puede acarrear problemas de seguridad.
Para asignar el permiso se usa el chmod con un 4 al principio.
chmod 4775 /micarpeta/ejecuta.shEl permiso aparecerá así:
ls -l ejecuta.sh
-rwsrwxr-x 1 eduardo eduardo 6 Jun 11 19:02 ejecuta.sh
chmod -x ejecuta.sh
ls -l ejecuta.sh
-rwSrw-r-- 1 eduardo eduardo 6 Jun 11 19:02 ejecuta.sh
Observamos que en la última línea le quitamos el servicio de ejecución al archivo y en los permisos se reemplaza la s minúscula por la S mayúsculas.
SGID
El bit SGID es lo mismo que SUID, pero a nivel de grupo. Esto es, todo archivo que tenga activo el SGID, al ser ejecutado, tendrás los privilegios del grupo al que pertenece.
Es bastante útil til queremos configurar un directorio para que colaboren diferentes usuarios. Si se aplica este bit al directorio, cualquier archivo creado en dicho directorio, tendrá asignado el grupo al que pertenece el directorio.
Para asignar el permiso se usa el chmod con un 2 al principio o con un
chmod g+s
O bien
chmod 2555 ejecuta.sh
Tipos de archivo en Linux por función
Cuando mostramos con el comando ls los inodos (archivos, directorios, enlaces, etc) del sistema de archivos en linux, no siempre todo está muy claro.
inodo o nodo índice es un elemento estructural propio de los sistemas de archivos empleado el sistemas tipo UNIX identificado de modo único y que contiene los atributos (nombre, fechas, ubicación, permisos de acceso, etc) del objeto de datos que pueda contener el sistema de ficheros:
en linux los tipos de objetos de datos (ficheros) son:
- '_' archivo regular (denotado por un guión en el inodo mostrado con ls)
- 'd' un directorio
- 'b' archivo especial de bloques (normalmente un dispositivo del almacenamiento o comunicación)
- 'c' archivo especial de caracteres
- 'l' enlace simbólico (link) a otro objeto de datos
- 'p' named pipe o "tubo nombrado"
- 's' socket de dominio
ls nos lo muestra de cada fichero en primer lugar lo que denominamos máscara de modo del fichero: una máscara de 16 bits que se muestra como una cadena de varios caracteres que indica la siguiente información:
Los primero 4 bits de información (bits 15-12) indican el tipo de fichero (descritos anteriormente) el comando ls nos lo muestra como el primer carácter de la cadena (-, d, b, c, l, p, s)
Atributos extendidos en los ficheros de Linux
Podemos clasificar los atributos extendidos en los de sistema que son los que proporcionan cualidades al archivo y los de usuario que permiten ampliar la información del archivo. También es aplicable a los directorios.
Atributos extendidos de sistema
Los sistemas de archivos ext2/3/4 permiten asignar a los ficheros unos atributos que modifican las cualidades o el comportamiento de los mismos. No son permisos, pero alguno de ellos realiza una función similar al limitar el poder modificar o eliminar su información. Estos atributos sólo son modificables por el administrador.
Para poder ver los atributos usaremos el comando lsattr:
Los atributos más comunes son:
- a: sólo append (sólo se pueden agregar datos, no modificar los existentes).
- A: no atime (no se mantiene la fecha y hora de acceso).
- d: no dump (se ignora al momento de hacer backups con el programa dump).
- D: el directorio se sincroniza a disco en cada escritura.
- i: inmutable (no se puede modificar, sólo renombrar o eliminar).
- S: el archivo se sincroniza a disco en cada escritura.
- e: extent, Indica que el archivo está utilizando extents para mapear los bloques en disco.
Para modificar un atributo se utiliza el comando chattr conjuntamente con “+[atributo]” o “-[atributo]” para añadirlo o eliminarlo.
Por ejemplo si queremos que no se pueda borrar o modificar el archivo prueba.txt:
chattr +i prueba.txtAtributos extendidos de usuario
Estos atributos no tienen ninguna influencia en los permisos de ficheros, añaden pares de clave-valor a los ficheros.
Para poder utilizarlos es necesario haber instalado el paquete attr y que el sistema de ficheros haya sido montado con la opción user_xattr.
Para añadir o quitar atributos usaremos el comando attr con las siguientes opciones:
- -ql: Lista todos los atributos
- -qs: Añade/Modifica atributos
- -qg: Muestra el valor de un atributo
- -qr: Elimina atributos
Por ejemplo añadamos el atributo “autor” al archivo fichero1.txt:
attr -qs autor -V “Etaboada” fichero1.txtPreservar los atributos extendidos
Debemos tener en cuenta que alguna de las operaciones que se realizan con los ficheros pueden eliminar los atributos extendidos, para evitarlo hay que agregar opciones especificas al comando:
|
cp |
–preserve=mode,ownership,timestamps,xattr |
|
mv |
Los preserva por defecto a excepción de que el destino no permita atributos extendidos |
|
tar |
–xattrs (para creación y extracción) |
|
bsdtar |
-p (para extracción) |
|
rsync |
–xattrs |
Filtrado de paquetes en Linux
Este capítulo se ocupará de la máquina de estado y la explicará en detalle.
La máquina de estado es una parte especial dentro de iptables que en realidad no debería llamarse máquina de estado, ya que en realidad es un seguimiento de conexiones. Sin embargo, la mayoría de la gente lo reconoce por el primer nombre. El seguimiento de la conexión se realiza para que el marco de Netfilter conozca el estado de una conexión específica. Los cortafuegos que implementan esto generalmente se denominan cortafuegos con estado. Un firewall con estado generalmente es mucho más seguro que los firewalls sin estado, ya que nos permite escribir conjuntos de reglas mucho más estrictos.
Los paquetes se pueden relacionar con conexiones rastreadas en cuatro estados diferentes. Estos se conocen como NEW, ESTABLISHED, RELATED and INVALID (NUEVOS, ESTABLECIDOS, RELACIONADOS y NO VÁLIDOS). Discutiremos cada uno de estos en profundidad más adelante. Con la coincidencia --state podemos controlar fácilmente quién o qué puede iniciar nuevas sesiones.
El seguimiento de la conexión se realiza mediante un marco especial dentro del kernel llamado conntrack
Todo el seguimiento de conexiones se maneja en la cadena PREROUTING, excepto los paquetes generados localmente que se manejan en la cadena OUTPUT. Lo que esto significa es que iptables hará todo el recalculo de estados y demás dentro de la cadena PREROUTING. Si enviamos el paquete inicial en un flujo, el estado se establece en NEW dentro de la cadena de OUTPUT, y cuando recibimos un paquete de retorno, el estado cambia en la cadena de ENRUTAMIENTO PREVIO a ESTABLECIDO, y así sucesivamente. Si el primer paquete no lo originamos nosotros, el estado NUEVO se establece dentro de la cadena PREROUTING. Por lo tanto, todos los cambios de estado y los cálculos se realizan dentro de las cadenas PREROUTING y OUTPUT de la tabla nat.
Como ha visto, los paquetes pueden adoptar varios estados diferentes dentro del propio núcleo, según el protocolo del que estemos hablando. Sin embargo, fuera del núcleo, solo tenemos los 4 estados descritos anteriormente. Estos estados se pueden usar principalmente junto con la coincidencia de estado que luego podrá hacer coincidir los paquetes en función de su estado de seguimiento de conexión actual. Los estados válidos son NUEVO, ESTABLECIDO, RELACIONADO y NO VÁLIDO. La siguiente tabla explicará brevemente cada estado posible.
| NEW | El estado NUEVO nos dice que el paquete es el primer paquete que vemos. Esto significa que se emparejará el primer paquete que vea el módulo conntrack, dentro de una conexión específica. Por ejemplo, si vemos un paquete SYN y es el primer paquete que vemos en una conexión, coincidirá. Sin embargo, el paquete también puede no ser un paquete SYN y aun así considerarse NEW. Esto puede generar ciertos problemas en algunos casos, pero también puede ser extremadamente útil cuando necesitamos recuperar conexiones perdidas de otros firewalls, o cuando una conexión está en timeout pero en realidad no está cerrada. |
| ESTABLISHED | El estado ESTABLISHED ha visto tráfico en ambas direcciones y luego coincidirá continuamente con esos paquetes. Las conexiones ESTABLISHED son bastante fáciles de entender. El único requisito para entrar en un estado ESTABLECIDO es que un host envíe un paquete y que luego reciba una respuesta del otro host. El estado NUEVO al recibir el paquete de respuesta a través del cortafuegos cambiará al estado ESTABLECIDO. Los mensajes de respuesta ICMP también pueden considerarse ESTABLECIDOS, si creamos un paquete que a su vez generó el mensaje ICMP de respuesta. |
| RELATED | El estado RELACIONADO es uno de los estados más complicados. Una conexión se considera RELACIONADA cuando está relacionada con otra conexión ya ESTABLECIDA. Lo que esto significa, es que para que una conexión se considere RELACIONADA, primero debemos tener una conexión que se considere ESTABLECIDA. La conexión ESTABLECIDA generará una conexión fuera de la conexión principal. La conexión recién generada se considerará RELACIONADA, si el módulo conntrack puede entender que está RELACIONADA. Algunos buenos ejemplos de conexiones que pueden considerarse RELACIONADAS son las conexiones de datos FTP que se consideran RELACIONADAS con el puerto de control FTP. Esto se usa para permitir que los mensajes de error ICMP, las transferencias FTP y los DCC funcionen correctamente a través del firewall. Ten en cuenta que la mayoría de los protocolos TCP y algunos protocolos UDP que se basan en este mecanismo son bastante complejos y envían información de conexión dentro de la carga útil de los segmentos de datos TCP o UDP y, por lo tanto, requieren módulos auxiliares especiales para entenderse correctamente. |
| INVALID | El estado NO VÁLIDO significa que el paquete no se puede identificar o que no tiene ningún estado. Esto puede deberse a varios motivos, como que el sistema se esté quedando sin memoria o que los mensajes de error de ICMP no respondan a ninguna conexión conocida. Generalmente, es una buena idea hacer DROP de todo en este estado. |
Iscsi debian
En primer lugar instalaremos los paquetes necesarios
apt update -y apt-get install open-iscsi multipath-tools
A continuación deberemos de tener acceso al portal iSCSI de nuestro almacenamiento. En nuestro caso usaremos por ejemplo la 10.0.15.x, como tenemos 8 caminos ya que disponemos de un almacenamiento con 8 interfaces iSCSI que serán 10.0.15.11-14 para la controladora A y 10.0.15.21-24 para la B
iscsiadm -m discovery -t sendtargets -p 10.0.15.11
multipath -ll
root@teststorage:/etc/multipath# multipath -ll mpath0 (3600c0ff00027f44e1231865801000000) dm-0 HP,MSA 2040 SAN size=8.2T features='3 queue_if_no_path queue_mode mq' hwhandler='1 alua' wp=rw |-+- policy='round-robin 0' prio=50 status=active | `- 2:0:0:0 sdb 8:16 active ready running `-+- policy='round-robin 0' prio=10 status=enabled |- 3:0:0:0 sda 8:0 active ready running `- 4:0:0:0 sdc 8:32 active ready running
iscsiadm -m discovery -t sendtargets -p 10.200.15.11
iscsiadm -m discovery -t sendtargets -p 10.200.15.14
iscsiadm -m node --login
nano multipath.conf
cat multipath.conf
Tenemos que buscar el wwid
nano /etc/multipath/wwids
Contendrá lo siguiente
# Multipath wwids, Version : 1.0 # NOTE: This file is automatically maintained by multipath and multipathd. # You should not need to edit this file in normal circumstances. # # Valid WWIDs: /3600c0ff00027f44e1231865801000000/
cat wwids
nano /etc/iscsi/iscsid.conf
iqn.1986-03.com.hp:storage.msa2040.162127e7a9
systemctl enable open-iscsi
systemctl enable iscsid
systemctl enable multipath-tools
iscsid open-iscsi
systemctl enable multipath-tools
nano /etc/multipath.conf
defaults {
find_multipaths "on"
polling_interval 2
path_selector "round-robin 0"
path_grouping_policy multibus
uid_attribute ID_SERIAL
rr_min_io 100
failback immediate
no_path_retry queue
user_friendly_names yes
}
blacklist {
devnode "^(ram|raw|loop|fd|md|dm-|sr|scd|st)[0-9]*"
devnode "^(td|hd)[a-z]"
devnode "^dcssblk[0-9]*"
devnode "^cciss!c[0-9]d[0-9]*"
device {
vendor "DGC"
product "LUNZ"
}
device {
vendor "EMC"
product "LUNZ"
}
device {
vendor "IBM"
product "Universal Xport"
}
device {
vendor "IBM"
product "S/390.*"
}
device {
vendor "DELL"
product "Universal Xport"
}
device {
vendor "SGI"
product "Universal Xport"
}
device {
vendor "STK"
product "Universal Xport"
}
device {
vendor "SUN"
product "Universal Xport"
}
device {
vendor "(NETAPP|LSI|ENGENIO)"
product "Universal Xport"
}
}
blacklist_exceptions {
wwid "3600c0ff00027f44e1231865801000000"
}
multipaths {
multipath {
wwid "3600c0ff00027f44e1231865801000000"
alias mpath0
}
}
Más información
https://elkano.org/blog/set-up-multipath-iscsi-targets-on-debian/
Balanceador con HAProxy y Keepalived
apt-get install keepalivednano /etc/keepalived/keepalived.confglobal_defs {
notification_email {
keepalived@ateinco.com.com
}
notification_email_from keepalived@ateinco.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id TESTATEINCO_DEVEL
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 1
weight -2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
mcast_src_ip 172.30.15.225
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 876543
}
virtual_ipaddress {
172.30.15.224/24 dev eth0 label eth0:1
}
track_interface {
eth0
}
track_script {
chk_haproxy
}
}apt-get install haproxynano /etc/haproxy/haproxy.cfg
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
# Default SSL material locations
ca-base /etc/ssl/certs
crt-base /etc/ssl/private
# See: https://ssl-config.mozilla.org/#server=haproxy&server-version=2.0.3&config=intermediate
ssl-default-bind-ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:E>
ssl-default-bind-ciphersuites TLS_AES_128_GCM_SHA256:TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256
ssl-default-bind-options ssl-min-ver TLSv1.2 no-tls-tickets
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
listen galera_cluster
bind 0.0.0.0:3306
mode tcp
#option tcplog
option tcpka
option mysql-check user haproxy
balance source
server db1 172.30.15.221:3306 check
server db2 172.30.15.222:3306 check
server db3 172.30.15.223:3306 check
listen http_cluster
bind 0.0.0.0:80
mode http
stats enable
#option tcplog
option httpchk GET /index.php HTTP/1.0
http-check expect rstatus (2|3)[0-9][0-9]|503
cookie PHPSESSID prefix indirect nocache
balance source
server web1 172.30.15.121:80 check
server web2 172.30.15.122:80 check
server web3 172.30.15.123:80 check
listen stats
bind 0.0.0.0:8080
mode http
option httplog
stats enable
stats uri /
stats realm Strictly\ Private
stats auth admin:adminInstalar Memcached
apt install memcached libmemcached-tools
nano /etc/memcached.confAhora desplázate hacia abajo y busca la siguiente línea y verifica el "-l" (dirección en la que eschucha) si este parámetro existe. Déjalo como predeterminado a menos que tengas una IP interna en una red local o una IP externa desde el exterior; debes modificar la dirección IP predeterminada de 127.0.0.1 a la nueva dirección IP.
-l 127.0.0.1
Suspensión del HDD en Linux hdparm
Puedes habilitar el modo de espera en un dispositivo de almacenamiento, desactivar el modo de espera por completo o ajustar el tiempo actual que tarda un disco duro en entrar en modo de espera. Esto ahorra consumo en discos de backup o que no están permanentemente en uso
Cada vez que un disco duro no tiene nada que hacer, espera un cierto período de tiempo y luego entra en modo de suspensión. Para ingresar al modo de suspensión/espera, un disco duro tiene que estacionar su cabezal y detener el giro de los platos.
Nota importante, el disco no debe estar montado para ejecutarlo
En primer lugar instalaremos hdparm
apt install hdparmAjustar el tiempo de espera de HDD con hdparm
Lo único que necesitas saber antes de comenzar es la ruta al archivo del dispositivo de la unidad para el que deseas configurar los ajustes
Para desactivar el modo de espera, se puede usar el siguiente comando hdparm.
hdparm -s 0 /dev/sdaPara ajustar la cantidad de tiempo de inactividad que transcurre antes de que un disco duro entre en modo de espera, usaremos la opción -S
Los valores posibles están entre 1-255. Multiplica el valor por 5 y obtendrás la cantidad de segundos a los que el disco duro entra en modo de espera.
hdparm -S 200 /dev/sda
/dev/sda:
setting standby to 200 (16 minutes + 40 seconds)
Parsear logs
Muchas veces los logs son inmensos y no hay forma de ver nada en ellos, por lo que usando determinadas herramientas podemos localizar lo que buscamos en los mismos
grep
GREP te permite ejecutar patrones de búsqueda en archivos. La sintaxis es muy sencilla
grep '<texto-buscado>' <archivo/archivos>Ten en cuenta que las comillas simples o dobles son imperativas alrededor del texto si es más de una palabra.
Puedes usar el comodín (*) para seleccionar todos los archivos en un directorio.
Ejemplo:
grep 'etaboada' maillog
Aug 13 07:30:53 vserver01016 XXXXXXX to=<etaboada@ateinco.net>
Aug 13 07:31:14 vserver01016 XXXXXXX to=<etaboada@ateinco.net>
Aug 13 08:54:11 vserver01016 xxxx-sendmail[11611]: S11611: from=<xxxxx> to=<etaboada@ateinco.net>
Aug 13 08:54:32 vserver01016 postfix/smtp[11622]: 505C0F217A9: to=<etaboada@ateinco.net> delay=21, delays=0.05/0.01/0.11/21, dsn=2.0.0, status=sent (250 OK id=1oMl2B-0003V5-2x)
Aug 13 09:00:01 vserver01016 xxxx-sendmail[12317]: S12317: from=<xxxxx@ateinco.net> to=<etaboada@ateinco.net>
Aug 13 09:00:22 vserver01016 postfix/smtp[12328]: 4C3A2F217A9: to=<etaboada@ateinco.net>, delay=21, delays=0.07/0.02/0.17/20, dsn=2.0.0, status=sent (250 OK id=1oMl7q-0003of-22)Zgrep
Funciona igual que grep, pero con la diferencia que permite buscar en archivos comprimidos
modificadores de grep
-n (--line-number)
enumera los números de línea, es decir imprime las coincidencias de un texto junto con los números de línea
grep 'etaboada' maillog -n
1492:Aug 13 07:30:53 vserver01016 XXXXXXX to=<etaboada@ateinco.net>
1514:Aug 13 07:31:14 vserver01016 XXXXXXX to=<etaboada@ateinco.net>
3646:Aug 13 08:54:11 vserver01016 xxxx-sendmail[11611]: S11611: from=<xxxxx> to=<etaboada@ateinco.net>
3654:Aug 13 08:54:32 vserver01016 postfix/smtp[11622]: 505C0F217A9: to=<etaboada@ateinco.net> delay=21, delays=0.05/0.01/0.11/21, dsn=2.0.0, status=sent (250 OK id=1oMl2B-0003V5-2x)
3804:Aug 13 09:00:01 vserver01016 xxxx-sendmail[12317]: S12317: from=<xxxxx@ateinco.net> to=<etaboada@ateinco.net>
3815:Aug 13 09:00:22 vserver01016 postfix/smtp[12328]: 4C3A2F217A9: to=<etaboada@ateinco.net>, delay=21, delays=0.07/0.02/0.17/20, dsn=2.0.0, status=sent (250 OK id=1oMl7q-0003of-22)-c (--count)
imprime el número de líneas de coincidencias
root@vserver:/var/log# grep 'etaboada' maillog -c
7-i (--ignore-case)
Utilizado para la ignorar la distinción entre mayúsculas y minúsculas
l (--files-with-matches)
imprimir nombres de archivos que coincidan con un patrón
-o (--only-matching)
imprimir solo el patrón coincidente
-A (--after-context) y -B (--before-context)
Imprimir las líneas después y antes (respectivamente) del patrón coincidente
-R (--dereference-recursive)
Búsqueda recursiva.
Por defecto, grep no busca en directorios. Si tú intentas hacerlo, obtendrás un error ("Es un directorio"). Con la opción -R, se realiza la búsqueda de archivos entre directorios y subdirectorios
^pattern Inicio de línea
Este patrón significa que grep solo coincide con cadenas cuyas líneas empiecen con la cadena especificada en pattern
pattern$ fin de la línea
Este patrón significa que grep solo coincide con cadenas cuyas líneas finalizan con la cadena especificada en pattern
Netstat
Comando netstat
Ver todas las conexiones
netstat -aroot@servidor:~# netstat -a | more
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 localhost:8084 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:ftp 0.0.0.0:* LISTEN
tcp 0 0 servidor.ateinco.l:domain 0.0.0.0:* LISTEN
tcp 0 0 servidor.ateinco.l:domain 0.0.0.0:* LISTEN
tcp 0 0 localhost:domain 0.0.0.0:* LISTEN
tcp 0 0 localhost:domain 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.53:domain 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:smtp 0.0.0.0:* LISTEN
tcp 0 0 localhost:953 0.0.0.0:* LISTEN
tcp 0 0 servidor.ateinco.loc:8443 0.0.0.0:* LISTEN
tcp 0 0 servidor.ateinco.lo:https 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:imaps 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:pop3s 0.0.0.0:* LISTEN
tcp 0 0 localhost:9000 0.0.0.0:* LISTEN
tcp 0 0 localhost:mysql 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:submission 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:5355 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:pop3 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:imap2 0.0.0.0:* LISTEN
tcp 0 0 localhost:spamd 0.0.0.0:* LISTEN
tcp 0 0 servidor.ateinco:http-alt 0.0.0.0:* LISTEN
tcp 0 0 servidor.ateinco.loc:http 0.0.0.0:* LISTEN
tcp 0 0 localhost:tproxy 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:submissions 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8083 0.0.0.0:* LISTEN
tcp 0 0 servidor.ateinco.loca:ssh unifidc.ateinco.l:57403 ESTABLISHED
tcp 0 0 servidor.ateinco.loca:ssh unifidc.ateinco.l:49156 ESTABLISHED
tcp6 0 0 localhost:domain [::]:* LISTEN
tcp6 0 0 localhost:domain [::]:* LISTEN
tcp6 0 0 fe80::d807:2cff::domain [::]:* LISTEN
tcp6 0 0 fe80::d807:2cff::domain [::]:* LISTEN
tcp6 0 0 [::]:ssh [::]:* LISTEN
tcp6 0 0 localhost:953 [::]:* LISTEN
tcp6 0 0 [::]:imaps [::]:* LISTEN
tcp6 0 0 [::]:pop3s [::]:* LISTEN
--More--Listado de conexiones TCP.
netstat -atListado de conexiones TCP.
netstat -auListado de todas las conexiones de puertos con la escucha activada
nestat -l
Túnel SSH
Muchas veces necesitamos acceder a una red remota, o bien navegar desde determinada IP para tareas como eliminar IP bloqueadas por envíos de correo no deseados. La forma de hacerlo es mediante un túnel SSH en el equipo que tiene dicha IP
Sintaxis
ssh -L <puerto-local-escucha>:<host-remoto>:<puerto-remoto> <servidor-ssh>Por ejemplo si queremos acceder a un servidor por Terminal Server que tiene bloqueados los accesos excepto en la red remota
Supongamos una máquina windows en la IP 10.0.100.250
sh -L 13389:10.0.100.10:3389 10.0.100.250Para ello deberemos habilitar el forwarding TCP en el SSH. EN nuestro archivo /etc/ssh/sshd.config. Deberemos comprobar que está habilitado
AllowTcpForwardingAdemás deberá estar habilitada la redirección del tráfico
sysctl net.ipv4.ip_forward=1
Localizar un disco físico mediante el led de actividad
Cuando tenemos que sustituir un disco, bien porque lo vamos a cambiar por otro mayor, o bien porque el disco está en fallo, o el estado SMART es de sugerencia de cambio, a veces nos encontramos que tenemos un servidor con múltiples discos, normalmente el orden se asigna según la bahía en la que se encuentra el disco, es decir
bahía0 /dev/sda, bahía1 /dev/sdb, etc
Pero para estar seguros de que disco es el que queremos cambiar, podemos ejecutar este comando que nos iluminará el led de actividad del disco correspondiente
while true; do dd if=/dev/disk/by-id/disco-en-fallo of=/dev/null; sleep 1; doneO bien solo iluminarlo durante un momento.
dd if=/dev/disk/by-id/disco-en-fallo of=/dev/nullOtro método es instalar la utilidad ledctl que se encuentra en el paquete Debian ledmon
Para ello instalaremos el paquete
apt install ledmon Y a continuación ejecutaremos ledctl para identificar el disco
ledctl locate=/dev/sdXSi queremos realizar la operación con varios discos a la vez
ledctl locate={ /dev/sdX /dev/sdY }
rsync
¿Tu rsync es lento? rsync tiene toneladas de opciones que se pueden afilar para mejorar el rendimiento, especialmente sobre ssh.
rsync -aHAXxv --numeric-ids --delete --progress -e "ssh -T -c aes128-ctr -m umac-64@openssh.com -o Compression=no -x" [source_dir] [dest_host:/dest_dir]Las opciones de rsync usadas son:
-
a: un clásico, el modo archivar. Copiar recursivamente directorios, preservar propietario, grupo, permisos y fechas, copia enlaces simbólicos y ficheros de dispositivo.
- H: preservar enlaces.
- A: preservar ACLs.
- X: preservar atributos extendidos.
- x: no pasar a otros sistemas de ficheros
- v: más cháchara
- --numeric-ds: no preservar uid/gid por nombre
- --delete: eliminar ficheros sobrantes de los directorios destino
- --progress: sacar una medida del progreso
ssh
- T: Desactivar pseudo-tty. Reduce carga en el destino.
- c aes128-ctr: usar el cifrado aes128-ctr, que es el más débil, pero el más rápido.
- m umac-64@openssh.com: usar el MAC umac-64, también el más rápido.
- o Compression=no: Quitar la compresión de ssh.
- x: desactivar reenvío de X, que está activo por defecto.
Instalar Redis
Precauciones antes de instalar Redis
Redis es un servicio de caché no autenticado por defecto, por lo que es MUY IMPORTANTE, que o se mantenga siempre escuchando por la IP 127.0.0.1 y no tenga salida al exterior (ni entrada) y que además procuremos usar una autenticación en el Redis
Ten en cuenta que cualquier script PHP que tenga acceso al Redis, al no ir autenticado, PUEDE ACCEDER A TODO
Instalar Redis
Instalar Redis en un servidor es una operación muy simple simplemente hay que ejecutar un apt get install
apt install redis-serverUna vez instalado al igual que con otros paquetes Debian, será necesario configurar que se inicie el servicio al reiniciar el equipo
systemctl enable redis-server
Nos saldrá el siguiente mensaje como que se ha activado el servicio de Redis al inicio
Synchronizing state of redis-server.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable redis-serverAhora procederemos a arrancarlo manualmente (puesto que no vamos a reiniciar el equipo)
systemctl start redis-serverPara comprobar que está funcionando, sólo tenemos que comprobarlo a través del redis-cli
root@tecnocratica:~# redis-cli
127.0.0.1:6379>Configurar Redis con Wordpress
En este artículo puedes ver un ejemplo de como configurar Wordpress para usar Redis
Autenticación en Redis
Para habilitar la autenticación en Redis, usaremos la opción requirepass
Para ello en nuestro fichero redis.conf que se encuentra en la carpeta etc, buscaremos esta opción
# requirepass foobarComo vemos está comentada, la descomentaremos y pondremos la clave que deseemos, por ejemplo:
requirepass HRk2h8NsUq41y5kcTambién podemos realizar esto desde el cliente de Redis
root@tecnocratica:~# redis-cli
127.0.0.1:6379>config set requirepass HRk2h8NsUq41y5kcAhora para conectarnos al Redis ejecutaremos:
root@tecnocratica:~# redis-cli
127.0.0.1:6379>AUTH HRk2h8NsUq41y5kcY ya podremos usar los comandos del cliente Redis
Instalar Chrony en Debian
Existen dos sistemas para mantener nuestros sistemas Debian correctamente sincronizados, por un lado tenemos ntp y como mejora al ntp también está chrony.
Al igual que ntp, chrony permite sincronizar fuentes de referencias externas para mantener la hora de los servidores, pero ambos tienen algunas diferencias.
Chrony permite sincronizar con servidores horarios externos y a la vez servir de fuente de hora para otros servidores de nuestra red. En el caso de ntp es sólo cliente y hay que instalar ntpd para que haga de servidor de hora.
Además chrony responde de forma más rápida y la sincronización tarda mucho menos, por lo que es ideal sobre todo para máquinas virtuales, que se pueden encender y apagar más a menudo.
Instalar chrony
Para instalar chrony ejecutaremos como siempre un simple comando, este instalará por si solo los dos sistemas (Chronyc y Chronyd) es decir el cliente y el demonio.
apt install chronyUna vez instalado, lo habilitaremos y lo ejecutaremos.
systemctl enable chrony
systemctl start chronyNota: antes de activar chrony, hay que deshabilitar y parar el servicio ntp y el ntpd en caso de que estuvieran instalados y habilitados
Para comprobar ejecutaremos
chronyc trackingNos dará una salida parecida a esta
# chronyc tracking
Reference ID : A29FC801 (time.cloudflare.com)
Stratum : 4
Ref time (UTC) : Sun Oct 08 09:50:10 2023
System time : 0.000003285 seconds slow of NTP time
Last offset : -0.000056454 seconds
RMS offset : 0.000053328 seconds
Frequency : 32.070 ppm slow
Residual freq : -0.001 ppm
Skew : 0.021 ppm
Root delay : 0.030552367 seconds
Root dispersion : 0.001204389 seconds
Update interval : 1025.7 seconds
Leap status : Normal
En esto podemos ver lo siguientes valores destacados:
Reference ID: Indica el ID de referencia y el nombre con el cual se sincroniza actualmente el equipo.
Stratum: número de saltos hacia un equipo usando el RefrenceID anterior.
Ref time (UTC): hora UTC en el cual se realizó la última medición de la fuente de referencia.
System Time: retraso del reloj del sistema desde el servidor sincronizado.
Last Offset: desplazamiento de la última actualización del reloj NTP.
RMS Offset: promedio a largo plazo del valor de compensación de tiempo.
Frequency: velocidad a la cual el reloj del sistema (el RTC) sería erróneo en caso de que chronyd no lo ajuste. las unidades van reflejadas en ppm (partes por millón).
Update interval: intervalos de sincronización en segundos.
Mostar fuentes de chrony
Usando el comando chronyc sources, podemos ver los servidores contra los que se sincroniza
chronyc sourcesEjemplo
root@eduardo:~# chronyc sources
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* time.cloudflare.com 3 10 377 455 -308us[ -364us] +/- 22ms
^- i2t15.i2t.ehu.eus 1 10 377 144 -1000us[-1000us] +/- 506ms
^+ cf393dbc-c70f-489d-a6e6-> 2 10 377 969 +164us[ +110us] +/- 45ms
^- 185.90.148.209 2 10 357 487 +5402us[+5346us] +/- 64msFichero de configuración de chrony
El fichero de configuración de chrony está en la carpeta /etc/chrony/chrony.conf como podemos ver en la siguiente imagen
En este fichero podemos configurar parámetros como por ejemplo el servidor o servidores (pool) que vamos a usar como referencia, los intervalos de sincronización, etc.
En este ejemplo, vemos que se usa el pool de debian. Si tenemos nuestros servidores en la red de Neodigit o de Tecnocrática, podemos usar ntp.neodigit.net como referencia.
Editamos el fichero, agregamos la línea server ntp.neodigit.net y reiniciamos chrony
# Include configuration files found in /etc/chrony/conf.d.
confdir /etc/chrony/conf.d
server ntp.neodigit.net
# Use Debian vendor zone.
pool 2.debian.pool.ntp.org iburst
Ahora comprobamos
root@eduardo:~# systemctl restart chrony
root@eduardo:~# chronyc sources
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^? res2.mad1.tecnocratica.n> 2 6 1 3 -509us[ -509us] +/- 34ms
^? ntp01.pingless.com 2 6 3 1 -614us[ -614us] +/- 18ms
^? cf393dbc-c70f-489d-a6e6-> 2 6 3 2 +211us[ +211us] +/- 43ms
^? i2t15.i2t.ehu.eus 1 6 3 2 -1023us[-1023us] +/- 506ms
root@eduardo:~# chronyc tracking
Reference ID : B2D7E418 (ntp01.pingless.com)
Stratum : 3
Ref time (UTC) : Sun Oct 08 10:08:08 2023
System time : 0.000000205 seconds fast of NTP time
Last offset : -0.000328478 seconds
RMS offset : 0.000328478 seconds
Frequency : 32.077 ppm slow
Residual freq : -22.917 ppm
Skew : 0.024 ppm
Root delay : 0.034075394 seconds
Root dispersion : 0.000739151 seconds
Update interval : 1.5 seconds
Leap status : Normal
Encontrar el número de serie de un disco en Linux
Muchas veces necesitamos localizar el número de serie de un determinado disco en Linux, sobre todo en los casos de esos servidores que alojan 24 o más discos.
Para localizar el número de serie, hay varias formas de hacerlo.
lsblk
El comando lsblk, nos permite obtener una lista de dispositivos de bloques en nuestro sistema
root@storageserver:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 465.8G 0 disk
├─sda1 8:1 0 1007K 0 part
├─sda2 8:2 0 512M 0 part
└─sda3 8:3 0 464.5G 0 part
sdb 8:16 0 7.3T 0 disk
├─sdb1 8:17 0 7.3T 0 part
└─sdb9 8:25 0 8M 0 part
sdc 8:32 0 7.3T 0 disk
├─sdc1 8:33 0 7.3T 0 part
└─sdc9 8:41 0 8M 0 part
sdd 8:48 0 7.3T 0 disk
├─sdd1 8:49 0 7.3T 0 part
└─sdd9 8:57 0 8M 0 part
sde 8:64 0 7.3T 0 disk
├─sde1 8:65 0 7.3T 0 part
└─sde9 8:73 0 8M 0 part
sdf 8:80 0 7.3T 0 disk
├─sdf1 8:81 0 7.3T 0 part
└─sdf9 8:89 0 8M 0 part
sdg 8:96 0 7.3T 0 disk
├─sdg1 8:97 0 7.3T 0 part
└─sdg9 8:105 0 8M 0 part
sdh 8:112 0 7.3T 0 disk
├─sdh1 8:113 0 7.3T 0 part
└─sdh9 8:121 0 8M 0 part
sdi 8:128 0 7.3T 0 disk
├─sdi1 8:129 0 7.3T 0 part
└─sdi9 8:137 0 8M 0 part
sdj 8:144 0 465.8G 0 disk
├─sdj1 8:145 0 1007K 0 part
├─sdj2 8:146 0 512M 0 part
└─sdj3 8:147 0 464.5G 0 part
sdk 8:160 0 7.3T 0 disk
├─sdk1 8:161 0 7.3T 0 part
└─sdk9 8:169 0 8M 0 part
sdl 8:176 0 7.3T 0 disk
├─sdl1 8:177 0 7.3T 0 part
└─sdl9 8:185 0 8M 0 part
sdm 8:192 0 7.3T 0 disk
├─sdm1 8:193 0 7.3T 0 part
└─sdm9 8:201 0 8M 0 part
sdn 8:208 0 7.3T 0 disk
├─sdn1 8:209 0 7.3T 0 part
└─sdn9 8:217 0 8M 0 partSi queremos obtener los números de serie, ejecutaremos
lsblk -o NAME,SERIALNos dará una salida parecida a esta, en la que vemos el nombre (sda,sdb,sdc,etc) y el número de serie a la derecha
root@storageserver:~# lsblk -o NAME,SERIAL
NAME SERIAL
sda S4CNNEXXXXXX55H
├─sda1
├─sda2
└─sda3
sdb XXXXX40PQ4R
├─sdb1
└─sdb9
sdc XXXXX40QHM1
├─sdc1
└─sdc9
sdd XXXXX40RCTD
├─sdd1
└─sdd9
sde XXXXX40REG1
├─sde1
└─sde9
sdf XXXXX40RR2L
├─sdf1
└─sdf9
sdg WD-XXXXX282LWK
├─sdg1
└─sdg9
sdh XXXXX0RDDP
├─sdh1
└─sdh9
sdi XXXXX8B49Y
├─sdi1
└─sdi9
sdj S4CNXXXXX50K
├─sdj1
├─sdj2
└─sdj3
sdk XXXXX0RQJW
├─sdk1
└─sdk9
sdl XXXXXGTWSBY
├─sdl1
└─sdl9
sdm XXXXX0QQPP
├─sdm1
└─sdm9
sdn XXXXX0RR26
├─sdn1
└─sdn9smartctl
La utilidad smartctl, nos permite además de mostrar el número de serie, realizar test y obtener información sobre el ciclo de vida de los discos. Si no está instalada, pordemos instalarla con:
apt install smartmontools E invocarla con smrtctl y el nombre del disco
smartctl -i /dev/sdbNos dará una salida como la que se muestra a continuación
root@storageserver:~# smartctl -i /dev/sdb
smartctl 7.3 2022-02-28 r5338 [x86_64-linux-6.2.16-14-pve] (local build)
Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Device Model: WDC WD80EFZZ-68BTXN0
Serial Number: WD-123456789
LU WWN Device Id: 5 0014ee 2157d3021
Firmware Version: 81.00A81
User Capacity: 8,001,563,222,016 bytes [8.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5640 rpm
Form Factor: 3.5 inches
Device is: Not in smartctl database 7.3/5319
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Thu Jan 4 14:39:20 2024 CET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Obtener el Número de Serie y el Modelo de un servidor en Linux - DMIDECODE
La utilidad DMIDECODE, nos permite obtener información sobre la plataforma que está ejecutando nuestro sistema operativo. Podemos ejecutarlo desde por ejemplo un USB de arranque si el equipo no dispone de un sistema operativo Linux de arranque.
Si ejecutamos dmidecode a secas, nos mostrará todos los parámetros de hardware del sistema, como procesador, número de serie, memoria RAM, etc.
Opciones de dmidecode
Obtener el número de serie
dmidecode -s system-serial-numberEjemplo
root@server:~# dmidecode -s system-serial-number
89AZXR42Obtener información sobre la RAM
Para esto ejecutaremos el comando
dmidecode --type 17O bien el comando
dmidecode -t memory La salida de este comando es como se muestra
root@a19:~# dmidecode --type 17
# dmidecode 3.4
Getting SMBIOS data from sysfs.
SMBIOS 2.7 present.
Handle 0x1100, DMI type 17, 34 bytes
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 8 GB
Form Factor: DIMM
Set: 1
Locator: DIMM_A1
Bank Locator: Not Specified
Type: DDR3
Type Detail: Synchronous Registered (Buffered)
Speed: 1333 MT/s
Manufacturer: 00XXXXXXXX
Serial Number: XXXXXXX
Asset Tag: 011XXXXX
Part Number: HMT3XXXXXXXR4A-H9
Rank: 2
Configured Memory Speed: 1333 MT/sPara mostrar sólo algunos parámetros podemos filtrar en el comando
Mostrar sólo velocidad
dmidecode -t memory | grep -i "speed"Ejemplo de salida
root@server:~# dmidecode -t memory | grep -i "speed"
Speed: 1333 MT/s
Configured Memory Speed: 1333 MT/s
Speed: 1333 MT/s
Configured Memory Speed: 1333 MT/s
Speed: 1333 MT/s
Configured Memory Speed: 1333 MT/s
Speed: 1333 MT/s
Configured Memory Speed: 1333 MT/s
Speed: 1333 MT/s
Configured Memory Speed: 1333 MT/s
Speed: 1333 MT/s
Configured Memory Speed: 1333 MT/sUpdate desde debian 11 a debian12
Comprobar versión
Para hacer un update de la versión debian 11 a debian 12, lo primero es comprobar la versión de debian que se está ejecutando. Para ello, ejecutaremos el comando
lsb_release -dLa salida nos dará la versión actualmente en ejecución
root@server:~# lsb_release -d
Description: Debian GNU/Linux 11 (bullseye)También puedes comprobar con el comando
cat /etc/debian_versionEl resultado será algo parecido a esto
root@h01019:~# cat /etc/debian_version
11.8Actualizar
Actualizar loss paquetes de Debian 11
Antes de actualizar de Debian bullseye a bookworm, es esencial asegurarse de que todos los paquetes existentes estén actualizados y actualizados a sus últimas versiones disponibles. Ejecutamos
apt updateapt upgradeapt dist-upgradeUna vez que se completen las actualizaciones, limpia los paquetes residuales y los archivos de configuración usando los siguientes comandos:
apt --purge autoremoveapt autocleanfind /etc -name '.dpkg-' -o -name '.ucf-' -o -name '*.merge-error'Con la introducción de numerosos paquetes nuevos, la versión Bookworm de Debian suspende y excluye varios paquetes antiguos que estaban presentes en Bullseye. Estos paquetes obsoletos no tienen una ruta de actualización designada. Por lo tanto, se recomienda reemplazar estos paquetes obsoletos con alternativas disponibles, si existieran.
Para identificar y eliminar "Paquetes obsoletos y creados localmente" ejecutaremos
apt list '~o'apt purge '~o'Después de esto deberemos reiniciar el sistema
Usando sed para actualizar
Ahora deberemos modificar los repositorios de bullseye y cambiarlos a bookworm, para ello usaremos sed
Es conveniente si no estás seguro hacer copia de seguridad de los archivos de apt list
Este comando utiliza la utilidad sed para reemplazar todas las apariciones de "bullseye" con "bookworm" en el archivo /etc/apt/sources.list.
sed -i 's/bullseye/bookworm/g' /etc/apt/sources.listActualiza las listas de fuentes de software adicionales en el directorio "sources.list.d" ejecutando el siguiente comando:
sed -i 's/bullseye/bookworm/g' /etc/apt/sources.list.d/*Además, debes agregar el repositorio de "firmware no gratuito" para compatibilidad con controladores de hardware.
sed -i 's/non-free/non-free non-free-firmware/g' /etc/apt/sources.listsed -i 's/non-free/non-free non-free-firmware/g' /etc/apt/sources.list.d/*Verifica si el archivo de lista de fuentes se ha actualizado con los nuevos enlaces del repositorio ejecutando el siguiente comando:
cat /etc/apt/sources.listLa salida del comando debe ser parecida a esta
deb http://deb.debian.org/debian/ bookworm main contrib non-free non-free-firmware
deb http://deb.debian.org/debian/ bookworm-updates non-free non-free-firmware contrib main
deb http://security.debian.org/debian-security bookworm-security main contrib non-free non-free-firmwareEjecutamos la actualización
Para actualizar, ejecutaremos un update de las fuentes
apt updatePrecaución (Opcional)
En ciertos escenarios, realizar una actualización completa del sistema como se explica en el siguiente paso puede eliminar una cantidad significativa de paquetes que deseas conservar. Por lo tanto, puedes realizar la actualización de dos partes que consta de una actualización mínima seguida de una actualización completa.
La actualización mínima garantiza la actualización de todos los paquetes existentes sin instalar ni eliminar ningún paquete adicional. Para iniciar la actualización mínima, usa el siguiente comando:
apt upgrade --without-new-pkgsAhora que las fuentes de paquetes se han actualizado, puedes actualizar el sistema.
Ejecuta el siguiente comando para realizar una actualización completa del sistema a Debian 12:
apt full-upgrade
Fichero de configuración para SSH
Os vamos a contar cómo crear y configurar un archivo de configuración OpenSSH para crear accesos directos a servidores a los que accedas con frecuencia en sistemas operativos Linux o Unix.
Puedes configurar tu cliente ssh OpenSSH utilizando varios archivos de la siguiente manera para ahorrar tiempo y escribir las opciones de línea de comandos del cliente ssh utilizadas con frecuencia, como puerto, usuario, nombre de host, archivo de identidad y mucho más para que sea más fácil acceder desde Linux/macOS o Unix.
Para ello crearemos un archivo en la carpeta .ssh llamado config
vi ~/.ssh/configSi queremos que sea accesible para todos los usuarios del sistema lo editaremos en la carpeta /etc/ssh/ssh_config (no confundir con el sshd_config)
Tienes que introducir un parámetro por línea y pueden estar separados por espacios o signos =
Para introducir comentarios puedes usar la # esas líneas se ignoran
Ejemplos
Host tecno01
HostName hosta26b29-02.tecnocratica.net
User eduardo
Port 22
Ahora podrás acceder tecleando simplemente ssh tecno01
En este caso vamos a usar un archivo .key diferente.
Host proxmox01
HostName 192.168.1.100
User root
IdentityFile ~/.ssh/proxmox.keyParámetros posibles
Host: Define para qué host o hosts se aplica la sección de configuración. La sección termina con una nueva sección de Host o al final del archivo.
HostName: especifica el nombre de host real para iniciar sesión. También se permiten direcciones IP numéricas.
User: Define el nombre de usuario para la conexión SSH.
IdentityFile: especifica un archivo desde el cual se lee la identidad de autenticación DSA, ECDSA o DSA del usuario. El valor predeterminado es ~/.ssh/identity para la versión 1 del protocolo y ~/.ssh/id_dsa, ~/.ssh/id_ecdsa y ~/.ssh/id_rsa para la versión 2 del protocolo. La opción IdentityFile en la configuración SSH o en la CLI se refiere al archivo de clave privada, que debe mantenerse confidencial.
Protocol: especifica las versiones de protocolo que ssh debe admitir en orden de preferencia. Los valores posibles son 1 y 2.
Puerto: especifica el número de puerto para conectarse en el host remoto.
Cipher: Cipher es un parámetro de la versión 1 del protocolo para indicar el tipo de cifrado para cifrar sesiones. Los tipos admitidos son Blowfish, des y 3des (predeterminado).
Ciphers: El parámetro Ciphers indica el tipo de cifrado para cifrar sesiones en la versión 2 del protocolo. Los cifrados disponibles y los valores predeterminados son:
aes128-ctr, aes192-ctr, aes256-ctr, arcfour256, arcfour128,
aes128-cbc, 3des-cbc, blowfish-cbc, cast128-cbc, aes192-cbc, aes256-cbc, arcfourHostKeyAlgorithms: El parámetro HostKeyAlgorithms establece el orden de preferencia para los algoritmos de clave de host en la versión 2 del protocolo. El orden predeterminado es ssh-rsa,ssh-dss.
Conectarse a equipos con SSH antiguos
Una de las principales ventajas de este archivo de configuración es la posibilidad de conectarse de forma fácil a equipos con versiones de RSA o protocolos SSH obsoletos
Ejemplos
Host switch-viejo
Hostname 192.168.3.14
user admin
HostKeyAlgorithms ssh-rsa
KexAlgorithms diffie-hellman-group1-sha1
port 22Host otro-sw-viejo
Hostname 192.168.37.254
user admin
HostKeyAlgorithms ssh-dss
KexAlgorithms diffie-hellman-group1-sha1
Ciphers +aes256-cbc
port 22
Host otro-sw-viejo-mas
Hostname 192.168.37.254
user admin
KexAlgorithms +diffie-hellman-group1-sha1
Ciphers aes128-ctr,aes192-ctr,aes256-ctr,aes128-cbc
PubKeyAcceptedKeyTypes +ssh-rsa
port 8122